
c++基础教程可以参考c++教程
c++编程中常见问题
new/delete,new[]/delete[]匹配问题
对于自定义类型
先说new[]会创建一个数组,一个对象数组需要一定的空间大小,假设一个对象需要N字节大小,K个对象的数组就需要K*N个空间来构造对象数组,但是在delete[]时候,如何知道数组的长度呢?
所以new[]会在KN个空间的基础上,头部多申请4个字节,用于存储数组长度,这样delete[]时候才知道对象数组的大小,才会相应调用K次析构函数,并且释放KN+4大小的内存。
delete,delete不同于delete[],它认为这只是一个对象占用的空间,不是对象数组,不会访问前4个字节获取长度,所以只调用了一次析构函数。而且,最后释放内存的时候只释放了起始地址为A的内存。然而这不是这一整块内存的起始地址,整块内存的起始地址应该是A-4,释放内存如果不从内存起始地址操作就会出现断错误。
隐藏的数据溢出
vector<int> vec;
vec.push_back(10);
for(auto i = vec.size(); i >= 0; i–)
cout << vec[i] << endl;
// 或者游戏币的溢出等等
// 内存类型与数据库数据类型不一致
// 大尺寸类型强转小尺寸类型
memcpy,memset 只使用与POD结构
复杂的用户自定义类型,直接内存操作,很容易损坏数据结构(如VTAB),或直接引用被拷贝对象的引用对象。
变量初始化问题
众所周知,局部变量在函数调用开始时创建,函数调用完成返回时“销毁”。值得注意的是,这里根本没有所谓的销毁、初始化的过程。局部变量的内存分配、回收是通过栈指针(esp)的减小、增大来完成的,注意函数栈从大地址向小地址增长。也就是说,函数栈只管分配和回收,至于这个地址空间里的内容, 它不关心,初始化工作要由程序员完成。同理,由malloc分配的空间,初始化工作也要由程序员完成。
使用未经初始化的变量,在写入值时,不会发生任何问题。但是在读取它的值时,就有可能发生错误。更要命的是,这种错误有可能在某段时间内、某个主机上(就是你的开发环境)一直不出现,一到测试环境、客户环境就会随机出现问题!由于局部变量的空间分配之前,可能被其他函数变量所用,这个空间的值刚好被置为0,这时再将这个空间分配给你的未初始化变量,就不会出现问题。而刚好在某一段时间内,函数调用流程是固定的,那么这个问题就“刚好”一直不会出现。但是我们不能一直跪地祈祷xx保佑不要出现问题,所以,记住这个血与泪的教训:定义变量时,一定要明确是否需要初始化。
问题示例:
#include <stdio.h>
void main_loop(int argc, char **argv)
{
int i;
while (i < argc)
{
i–;
}
}
int main(int argc, char *argv[])
{
main_loop(argc, argv);
return 0;
}
初始化示例:
int i = 0;
int *p = NULL;
char buf[1024] = {0};
struct st_ipc ipc;
memset(&ipc, 0, sizeof(ipc));
实参合法性判断问题
在开发api给其他人用,或者自己封装api时,往往要注意实参的检查。最常见的是指针、数据范围的判断。这是增强程序健壮性的必备手段。而在每个函数入口检查参数,自然会有一堆重复代码。这时候宏的作用就体现出来了:
#ifdefine DEBUG_EN
#define DEBUG(fmt, args…) \
do { \
printf(“DEBUG:%s-%d-%s “fmt, __FILE__, __LINE__, __FUNCTION__, ##args);\
}while(0)
#define ERROR(fmt, args…) \
do { \
printf(“ERROR:%s-%d-%s “fmt, __FILE__, __LINE__, __FUNCTION__, ##args);\
}while(0)
#else
#define DEBUG(fmt, args) do{}while(0)
#define ERROR(fmt, args) do{}while(0)
#endif
#define IS_NULL(p) (p == NULL)
#define P_VALID_CHECK_ACT(p, act) {if (IS_NULL(p)){DEBUG(#p” is NULL\n”);act;}}
#define P_VALID_CHECK_RET(p, ret) P_VALID_CHECK_ACT(p, return ret)
如果参数非法,将提示出问题的代码文件、行数、所在的函数,方便定位问题。
使用方法:
int func(char *str)
{
P_VALID_CHECK_RET(str, -1);
…
return 0;
}
int fuc1(char *str)
{
int ret = -1;
P_VALID_CHECK_ACT(str, goto ret);
ret: // 这个不提倡
return ret;
}
赋值问题
这里主要是==和=的混用,比如条件判断时,误赋值的问题,比如:
if (a = 0 || c > d) {
//…
}
或者
int set(int *a)
{
if(/*…*/)
*a == 1;
}
解决办法:
if (0 == a || c > d) {
//…
}
内存问题
这是个常见的、烦人的、一两句话说不清的问题。主要是要注意几点:
- 空间由谁释放、在哪里释放,释放之后不应该再访问那块空间,不能再次释放已经释放的空间。只能手动释放分配在堆上的空间。
#define SAFE_FREE(p) {if (p){free(p);p=NULL;}}
- 空间由谁分配,分配了多大空间,不能访问范围之外的空间。
- 不要解引用为空的指针。在使用指针访问其成员之前,先检查指针是否为空。
- C风格的字符串,分配内存时,没有加上‘\0’(strlen(char*) + 1);由于意外原因拷贝字符串时,没有留下’\0’,导致读越界。
- 内存泄漏,new的对象指针,没有被释放就被意外赋予新的地址;忘记删除指针;或者发生异常没有机会释放内存等。可使用unique_ptr等智能指针。不过全局对象指针,在应用程序退出时,会被系统回收,但是不要养成依赖系统这样的习惯,有些系统资源是需要手动释放的。
- 一次申请,多次删除;比如,一次申请了一个对象,但是赋给了原生指针,后又赋值给职能指针,但是删除了原生指针等。
- 内存泄漏检测工具,vc自带内存检测工具,此外还有更多类似valgrind这样的第三方内存检测工具。
- 栈空间耗尽,比如,在函数体内,申请了一大块数组空间,超过了默认的栈空间大小。会导致堆栈溢出。
STL容器遍历删除时注意迭代器失效问题
void erase(vector<int> & vec, int a)
{
// 正确的用法
for(auto it = vec.begin(); it != vec.end(); )
{
if(*it == a)
{
it = vec.erase(it);
}
else
++it;
}
// 错误的做法
for(auto it = vec.begin(); it != vec.end(); ++it)
{
if(*it == a)
{
vec.erase(it);
}
}
}
类型转换
在C++中尽量使用C++风格的四种类型转换,而不要使用C语言风格的强制类型转换Static_cast, const_cast, dynamic_cast, interpret_cast
异步操作
std::async 这货返回的 future 和通过 promise 获取的 future 行为不同,async 返回的 future 对象在析构时会阻塞等待 async 中的线程执行完毕。
async(launch::async, []{f();}); // 注意不要绑定临时变量
async(launch::async, []{g();}); // g,等待f完成
智能指针
一个裸指针不要使用多个智能指针包裹,尽可能使用make_unique,make_shared。当需要在类得内部接口中,需要将this作为智能指针使用,需要用该类派生自enable_shared_from_this
栈内存
使用合理使用栈内存,特别是数组,数组越界问题容易导致栈空间损坏,可以考虑使用std::array替代普通的数组。
##
一定要记得join或这detach,否则会crash。
void func() {}
int main() {
std::thread t(func);
if (t.joinable()) {
t.join(); // 或者t.detach();
}
return 0;
}
网络通信类
tcp/udp
假设我们采用如下的tlv数据结构通信:
struct fs_tlv{
u_int16_t type;
u_int32_t length;
char value[0];
}__attribute__((__packed__));
#define FS_TLV_HLEN sizeof(struct fs_tlv)
struct fs_msg_h{
u_int16_t type;
u_int32_t length;
u_int16_t id;
char value[0];
}__attribute__((__packed__));
#define FS_MSG_HLEN sizeof(struct fs_msg_h)
一般情况下,一个完整的消息由消息头和数据构成(注意这里取消了内存对齐)。一般的处理是:数据准备好读取时,我们先读取消息头,确定后面的数据长度,再根据这个长度分配一个空间,再读取后面的数据。这样可以避免不必要的空间浪费。在使用tcp协议时,这样做完全没有问题。tcp是一种面向连接的、可靠的、基于字节流的通信协议。“字节流”意味着你甚至可以一个字节一个字节地读取数据,当然,考虑到效率问题,一般不这么做。
但如果通信协议是udp时,情况就不同了。你必须一次读取尽可能多的数据,如果你只读取了消息头(数据包的一部分),那么整个数据包都会丢失。第二次读取数据部分时,将出现问题。udp是用户数据报协议,有不提供数据包分组、组装和不能对数据包进行排序的缺点。使用udp意味着由应用层保证传输可靠性,值得注意的是,使用udp传输数据,数据包应该尽可能的小。
大端小端
大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,类似于字符串的存放。相反小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中。大端格式更符合我们的习惯。
什么是数据的高字节?什么是低字节?什么是内存的高地址?低地址?
对于数字来说,比如十六进制的0x1234,数据的高字节指的是权值高的字节(显然1的权值高于4),12是高字节,34是低字节。内存地址大的为高地址,小的为低地址。这个数字用大端模式表示就是:12 34, 小端模式时:34 12。而对于字符串,是按照出现顺序,在左边的先发送,先收到。不存在大端小端转换的问题,因为字符串的解析,不依赖与字符串的长度,而是一个字节一个字节地解析。
网络通信采用的是网络字节序,具体就是大端格式。在发送、接收大于1字节的基本数据类型数据时,要注意使用ntoh、hton一类的函数转换字节序。
结构体内存对齐
一般在通信编程中, 会采用结构体来封包、解包。这样可以避免复杂的指针运算、类型转换等操作。而不同的内存对齐方式,结构体的大小是不同的,结构体成员相对于结构体的起始地址也不相同。因为不同的对齐方式,可能在成员之间填充不同字节大小的空间。而采用内存对齐,主要是优化处理器访问,减少访问次数,提高速度。但是这个效率的提高,可能带来的是通信异常、不必要的空间浪费(填充字节),得不偿失,而且通信双方采用相同的对齐方式,这个也无法保证。所以一般在定义结构体时指定
__attribute__((__packed__)) // gnu c
//__attribute__((aligned(4))) 可指定4字节对齐
#pragma pack(1) // vc
//#pragma pack(4) 4 字节对齐
采用1字节对齐(常用于协议字节流的解析,将网络字节流转化为struct后,解析出相关的属性);特别注意。
加密解密
网络通信中经常会用到诸如MD5的加密api, 典型的加密流程:
#include <stdio.h>
#include “md5.h”
int main(void)
{
struct MD5Context md5;
char s[] = “helloworld”;
unsigned char ss[16];
int i = 0;
char buf[128] = {0};
MD5Init(&md5);
MD5Update(&md5, s, strlen(s));
MD5Final(ss, &md5);
for (i = 0; i < sizeof(ss); i++)
sprintf(buf + 2*i, “%02X”, ss[i]);
printf(“%s\n”, buf);
return 0;
}
输出结果:FC5E038D38A57032085441E7FE7010B0
这里有几个值得注意的地方:
- void MD5Update (MD5_CTX *context, unsignedchar *input, unsignedlong InputLen); 注意这里的InputLen为input字符串的长度, 而非占用的空间(多了’\0’)。如果第11行的strlen换成sizeof的话,就悲剧了,加密结果总是错的。而很多人会想当然的用sizeof,因为大多数传入指针的函数确实是要求传入这个指针指向空间的大小。
- 参数input的类型是unsigned char, 可接受字符串、或二进制数。再次证明了第一点,第三个参数不可能是字符串长度。
- void MD5Final (unsignedchar *digest, MD5_CTX *context);生成最终的加密结果,注意结果digest的类型是unsigned char,不是字符串,不能直接解析为字符串,而是整数值!也就是说,这里使用unsigned char,只是当做了大小1字节的无符号整数来使用。
- 还是上面unsigned char的问题,如果ss定义为char类型,那么sprintf(buf, “%X”, ss[i]);就极有可能出现问题,假如ss[i]的值大于7f,符号位就为1,而%X表示以无符号整数输出,char转换为usigned int将会发生符号扩展,结果会看见很多FF…所以这里使用了%02X,限制了只输出低2位16进制数,不足2位用0填充。
函数类
sizeof
sizeof是编译期计算数据类型的内存尺寸的,比如:数组名在函数传递参数过程中, sizeof(数组名)得到的是这个指针变量占用的空间,而非数组占用的空间。切记不要(char*)与strlen混淆。
可变参数的函数
vsprintf函数用于解析格式控制符一类的参数,有内存溢出的风险。曾遇到有人利用这个漏洞执行了恶意代码,拿到了设备控制权限。解决办法是利用vsnprintf代替。
system
这个问题其实不能归结于system函数的问题,应该是Linux shell(sh、bash)向某个程序传递命令行参数时要注意的问题。有时一个参数比如文件名中可能包含空格、中文字符,而一般多个参数是用空格隔开的,这种情况下就会造成参数传递错误。可使用新版本的c++字面变量。
static void custom_fload(void)
{
char cmdline[1024] = {0};
sprintf(cmdline, “ln -sf \”%s\” \”%s\””, “Hello world”, “custom_f”);
system(cmdline);
return;
}
解决办法是,在可能出现空格、中文字符的参数前后加上双引号,明确双引号包围的字符为一个参数。
一般情况下,我们调用system去执行一些零时的、不重要的命令。由于system会继承环境变量,在编写SUID/SGID 权限的程序时可能会遇到问题,此外,system所执行的命令是否执行成功的判断略繁琐,所以在使用时要多多注意。
编译类
c标准
曾经遇到过一个排查了很久才偶然解决的BUG, 为了支持某些新特性,在gcc编译时指定了-std=c99参数,编译时一切正常。遇到一个基于unix域协议的ipc函数调用时,发现通信过程中,某个结构体成员的值总是不正确。仔细排查发现,ipc函数调用在一个动态链接库中,是之前单独使用gcc默认c标准编译的(c89/c90)标准。去掉-std=c99参数之后,BUG消失。怀疑是不同c标准下产生的二进制代码不同, 在进程通信时,可能会带来兼容问题。新版本的c++,需要使用c14/17等。
makefile
编辑一个目标下所执行的命令时,必须使用Tab键缩进!并且禁止编辑器使用空格代替Tab键!推荐使用cmake
头文件
一定要在文件头尾使用宏防止头文件被重复包含
#ifndef _APP_IGD_AP_H_
#define _APP_IGD_AP_H_
…..
#endif
// vc
#pramga once
c++高阶话题
高阶部分,可提供给有c++基础的程序员阅读。
元编程
模板是对代码的描述
基础
在 C++ 中,我们一共可以声明(declare) 5种不同的模板,分别是:类模板(class template)、函数模板(function template)、变量模板(variable template)、别名模板(alias template)、和概念(concept)。
// declarations
template <typename T> struct class_tmpl;
template <typename T> void function_tmpl(T);
template <typename T> T variable_tmpl; // since c++14
template <typename T> using alias_tmpl = T; // since c++11
template <typename T> concept no_constraint = true; // since c++20
//
// definitions
template <typename T> struct class_tmpl {};
template <typename T> void function_tmpl(T) {}
template <typename T> T variable_tmpl = T(3.14);
// 下面注意了;泛型 lambda来了,hh
// NOTE: Generic lambda (since c++14) is NOT a template,
// its operator() is a member function template.
auto glambda = []<typename T>(T a, auto&& b) { return a < b; };
// alias
template <bool B> using bool_constant = integral_constant<bool, B>;
using true_type = bool_constant<true>;
using false_type = bool_constant<false>;
在模板中,我们可以声明三种类型的 形参(Parameters),分别是:非类型模板形参(Non-type Template Parameters)、类型模板形参(Type Template Parameters)和模板模板形参(Template Template Parameters):
// There are 3 kinds of template parameters:
template <int n> struct NontypeTemplateParameter {};
template <typename T> struct TypeTemplateParameter {};
template <template <typename T> typename Tmpl> struct TemplateTemplateParameter {};
其中,非类型的形参接受一个确定类型的常量作为实参(Arguments),例如在上面的例子中,模板 NontypeTemplateParameter 接受一个 int 类型的常量。更一般地,非类型模板形参必须是 结构化类型(structural type)的,主要包括:
- 整型,如 int, char, long
- enum 类型
- 指针和引用类型
- 浮点数类型和字面量类型(C++20后)
要注意的是,非类型模板实参必须是常量,因为模板是在编译期被展开的,在这个阶段只有常量,没有变量。
template <float &f>
void foo() { std::cout << f << std::endl; }
template <int i>
void bar() { std::cout << i << std::endl; }
int main() {
static float f1 = 0.1f;
float f2 = 0.2f;
foo<f1>(); // output: 0.1
foo<f2>(); // error: no matching function for call to ‘foo’, invalid explicitly-specified argument.
int i1 = 1;
int const i2 = 2;
bar<i1>(); // error: no matching function for call to ‘bar’,
// the value of ‘i’ is not usable in a constant expression.
bar<i2>(); // output: 2
}
对于类型模板形参(Type Template Parameters),我们使用 typename 关键字声明它是一个类型。对于模板模板形参(Template Template Parameters),和类模板的声明类似,也是在类型的前面加上 template <…>。模板模板形参只接受类模板或类的别名模板作为实参,并且实参模板的形参列表必须要与形参模板的形参列表匹配。
template <template <typename T> typename Tmpl>
struct S {};
template <typename T> void foo() {}
template <typename T> struct Bar1 {};
template <typename T, typename U> struct Bar2 {};
S<foo>(); // error: template argument for template template parameter
// must be a class template or type alias template
S<Bar1>(); // ok
S<Bar2>(); // error: template template argument has different template
// parameters than its corresponding template template parameter
变长形参列表
一个模板可以声明多个形参,更一般地,可以声明一个变长的形参列表,称为 “template parameter pack”,这个变长形参列表可以接受 0 个或多个非类型常量、类型、或模板作为模板实参。变长形参列表必须出现在所有模板形参的最后。
// template with two parameters
template <typename T, typename U> struct TemplateWithTwoParameters {};
// variadic template, “Args” is called template parameter pack
template <int… Args> struct VariadicTemplate1 {};
template <int, typename… Args> struct VariadicTemplate2 {};
template <template <typename T> typename… Args> struct VariadicTemplate3 {};
VariadicTemplate1<1, 2, 3>();
VariadicTemplate2<1, int>();
VariadicTemplate3<>();
实例化
模板的实例化(Instantiation)是指由泛型的模板定义生成具体的类型、函数、和变量的过程。模板在实例化时,模板形参被替换(Substitute)为实参,从而生成具体的实例。模板的实例化分为两种:按需(或隐式)实例化(on-demand (or implicit) instantiation) 和 显示实例化(explicit instantiation),其中隐式的实例化是我们平时最常用的实例化方式。隐式实例化,或者说按需实例化,是当我们要用这个模板生成实体的时候,要创建具体对象的时候,才做的实例化。而显式实例化是告诉编译器,你帮我去实例化一个模板,但我现在还不用它创建对象,将来再用。要注意,隐式实例化和显式实例化并不是根据是否隐式传参而区分的。自 C++11 后,新标准还支持了显式的实例化声明(explicit instantiation declaration)这一特性。
// t.hpp
template <typename T> void foo(T t) { std::cout << t << std::endl; }
// t.cpp
// on-demand (implicit) instantiation
#include “t.hpp”
foo<int>(1);
foo(2);
std::function<void(int)> func = &foo(int);
// explicit instantiation
#include “t.hpp”
template void foo<int>(int);
template void foo<>(int);
template void foo(int);
当使用模板,触发了一个实例化过程时,编译器就会用模板的实参(Arguments)去替换(Substitute)模板的形参(Parameters),生成对应的代码。编译器会根据一定规则选择一个位置,将生成的代码插入到这个位置中,这个位置被称为 POI(point of instantiation);编译器一定要能看到模板的定义,才能对其进行替换,完成实例化;因此,编译器一定要能看到模板的定义,才能对其进行替换,完成实例化;故而,一般会将模板定义在头文件中,然后再源文件中 #include 头文件来获取该模板的定义。但是这样做,会带来两个负面问题:
- 链接时的重定义问题,如果不加以处理,这些相同的实体会被链接器认为是重定义的符号,这违反了ODR(One Definition Rule)。对这个问题的主流解决方案是为模板实例化生成的实体添加特殊标记,链接器在链接时对有标记的符号做特殊处理。例如在 GNU 体系下,模板实例化生成的符号都被标记为弱符号(Weak Symbol)。
- 编译时长的问题,同一个模板传入相同实参在不同的编译单元下被实例化了多次,这是不必要的,浪费了编译的时间。
模板特化
模板的特化(Template Specialization)允许我们替换一部分或全部的形参,并定义一个对应改替换的模板实现。其中,替换全部形参的特化称为全特化(Full Specialization),非特化的原始模板称为主模板(Primary Template)。只有类模板和变量模板可以进行偏特化,函数模板只能全特化。在实例化模板的时候,编译器会从所有的特化版本中选择最匹配的那个实现来做替换(Substitution),如果没有特化匹配,那么就会选择主模板进行替换操作。
// function template
template <typename T, typename U> void foo(T, U) {} // primary template
template <> void foo(int, float) {} // full specialization
// class template
template <typename T, typename U> struct S {}; // #1, primary template
template <typename T> struct S<int, T> {}; // #2, partial specialization
template <> struct S<int, float> {}; // #3, full specialization
S<int, int>(); // choose #2
S<int, float>(); // choose #3
S<float, int>(); // choose #1
// 我们可以只声明一个特化,然后在其他的地方定义它:
template <> void foo<float, int>;
template <typename T> struct S<float, T>;
// 特化声明与显式实例化(explicit instantiation)的语法非常相似,注意不要混淆了。
// Don’t mix the syntax of “full specialization declaration” up with “explict instantiation”
template void foo<int, int>; // this is an explict instantiation
template <> void foo<int, int>; // this is a full specialization declaration
函数模板重载
函数模板虽然不能偏特化,但是可以重载(Overloading),并且可以与普通的函数一起重载。在 C++ 中,所有的函数和函数模板,只要它们拥有不同的签名(Signature),就可以在程序中共存。一个函数(模板)的签名包含下面的部分:
- 函数(模板)的非限定名(Unqualified Name)
- 这个名字的域(Scope)
- 成员函数(模板)的 CV 限定符
- 成员函数(模板)的 引用限定符
- 函数(模板)的形参列表类型,如果是模板,则取决于实例化前的形参列表类型
- 函数模板的返回值类型
- 函数模板的模板形参列表
所以,根据这个规则,下列的所有函数和函数模板foo,都被认为是重载,而非重定义:
template <typename T> void foo(T) {} // #1
template <typename T> void foo(T*) {} // #2
template <typename T> int foo(T) {} // #3
template <typename T, typename U> void foo(T) {} // #4
template <typename T, typename U> void foo(T, U) {} // #5
template <typename T, typename U> void foo(U, T) {} // #6
void foo(int) {} // #7
void foo(float, int) {} // #8
// 注意:上述 #5 和 #6 两个模板不是重定义,但在调用的时候仍有可能触发一个歧义错误,编译器有时无法决定两个函数模板哪个的重载优先级更高
foo(1); // call #7
foo(new int(1)); // call #2
foo(1.0f, 1); // call #8
foo<int, float>(1, 1.0f); // call #5
foo(1, 1.0f); // error: ambiguous
注意事项或约定
1、匹配特化版本,既要满足正向推导(代入特化);又要满足反向推导
2、析取表达式的求值与运行时不同,运行时的析取表达式遵循“短路求值(short-circuit evaluation)”的规则,对 a || b 如果 a 为 true,就不再对 b 求值了。但是在编译期,在模板实例化的时候,析取表达式的短路求值是不生效的。
template <typename T, typename U, typename… Rest>
struct is_one_of : bool_constant<is_one_of<T, U>::value || is_one_of<T, Rest…>::value> {};
template <typename T, typename U>
struct is_one_of<T, U> : is_same<T, U> {};
int i = 0;
std::cout << is_one_of_v<decltype(i), float, double> << std::endl; // 0, #1
std::cout << is_one_of_v<decltype(i), float, int, double, char> << std::endl; // 1, #2
// 对于#2,在遍历到 bool_constant<is_one_of<int, int> || is_one_of<int, double, char>> 的时候,虽然前面的表达式已经可以确定为 true 了,但是后半部分的表达式 is_one_of<int, double, char> 依旧会被实例化。
怎样优化这个问题呢,可使用conditional
template<bool B, typename T, typename F>
struct conditional : type_identity<T> {};
template<typename T, typename F>
struct conditional<false, T, F> : type_identity<F> {};
// With conditional, we can implement a “short-circuited” is_one_of.
// For is_one_of<int, float, int, double, char>,
// is_one_of<int, double, char> will NOT be instantiated.
template <typename T, typename U, typename… Rest>
struct is_one_of : conditional_t<
is_same_v<T, U>, true_type, is_one_of<T, Rest…>> {};
template <typename T, typename U>
struct is_one_of<T, U> : conditional_t<
is_same_v<T, U>, true_type, false_type> {};
这个技巧可以用来优化编译时长。
3、待决名(Dependent Name),比如,remove_reference<T>::type 是一个待决名,编译器在语法分析的时候还不知道这个名字到底代表什么。对于普通的名字,编译器直接通过名字查找就能知道这个名字的词性。但对于待决名,因为它是什么取决于模板的实参 T,所以直到编译器在语义分析阶段对模板进行了实例化之后,它才能对“type”进行名字查找,知道它到底是什么东西,所以名字查找是分两个阶段的,待决名直到第二个阶段才能被查找。但是在语法分析阶段,编译器就需要判定这个语句是否合法,所以需要我们显式地告诉编译器 “type” 是什么。在 remove_reference<T>::type 这个语法中,type 有三种可能,一是静态成员变量或函数,二是一个类型,三是一个成员模板。编译器要求对于类型要用 typename 关键字修饰,对于模板要用 template 关键字修饰,以便其完成语法分析的工作。
template <typename T> struct remove_reference { using type = T; }; // #1
template <typename T> struct remove_reference<T&> { using type = T; }; // #2
template <typename T> struct remove_reference<T&&> { using type = T; }; // #3
// case 1:
int&& i = 0;
remove_reference<decltype(i)>::type j = i; // equivalent to: int j = i;
// case 2:
template <typename T>
void foo(typename remove_reference<T>::type a_copy) { a_copy += 1; }
foo<int>(i); // passed by value
foo<int&&>(i); // passed by value
4、元函数/功能(Metafunction),比如,is_reference 和 remove_reference 是两个类模板,但是在 TMP 中,它们接受实参,返回结果,是像函数一样地被使用。我们称这种在编译期“调用”的特殊“函数”为 Metafunction,它代表了 TMP 中的“逻辑”。Metafunction 接受常量和类型作为参数,返回常量或类型作为结果,我们称这些常量和类型为Metadata,它代表了 TMP 中的“数据”。进一步地,我们称常量为 Non-type Metadata (or Numerical Metadata),称类型为 Type Metadata。为此,有约定如下:所有的 Metafunction 都以 “type” 作为唯一的返回值,对于原本已 “value” 指代的那些常量,使用一个类模板将它们封装起来,Metafunction 返回这个类模板的相应实例。
// non-type metadata (or numerical metadata)
template <bool b>
struct bool_ { static constexpr bool value = b; };
// metafunction
template <typename T> struct is_reference { using type = bool_<false>; };
template <typename T> struct is_reference<T&> { using type = bool_<true>; };
template <typename T> struct is_reference<T&&> { using type = bool_<true>; };
所以,在调用 is_reference 时,也是使用 “type” 这个名字,如果想访问结果中的布尔值,使用 is_reference<T>::type::value 即可。
5、使用struct和public 继承
我们在元编程,定义类模板时,经常看到使用struct关键字,而不是class;其实这是个惯例,因为这样可以省去继承和内部的public关键字。同时,继承的时候不仅 “type” 成员被继承过来了,“value” 也被继承了过来。我们在 TMP 中会尽可能地使用这种继承的方式,而不是每次都去定义type。因为这种方式实现的代码更简洁,也更具有一致性:当一个 Metafunction 依赖另一个 Metafunction 时,就是应该直接获取另一个 Metafunction 的全部内容。
也既,当一个 Metafunction 使用另一个 Metafunction 的结果作为返回值时,不用自己定义 type 成员了,只需要直接继承另一个 Metafunction 即可。
template <typename T>
struct type_identity { using type = T; };
type_identity<int>::type i; // equivalent to: int i;
// with type_identity, we can implement remove_reference like this:
template <typename T> struct remove_reference : type_identity<T> {};
template <typename T> struct remove_reference<T&> : type_identity<T> {};
template <typename T> struct remove_reference<T&&> : type_identity<T> {};
6、使用别名
为了方便,我们通常还会创建两个东西来简化 Metafunction 的调用。
对于返回非类型常量的 Metafunction,我们定义一个 _v 后缀的变量模板(Variable Template),通过它可以方便地获取 Metafunction 返回的 value:
// variable template
template <typename T> inline constexpr bool is_reference_v = is_reference<T>::value;
对于返回一个类型的 Metafunction,我们声明一个 _t 后缀的别名模板(Alias Template),通过它可以方便地获取 Metafunction 返回的 type:
// alias template
template <typename T> using remove_reference_t = typename remove_reference<T>::type;
效果如下:
std::cout << is_reference_v<remove_reference_t<int&&>> << std::endl; // output: 0
lambda表达式
语法
|
Syntax |
Remark No |
C++ Version |
|
[ captures ] ( params ) lambda-specifiers requires(optional) { body } |
(1) |
|
|
[ captures ] { body } |
(2) |
(until C++23) |
|
[ captures ] lambda-specifiers { body } |
(2) |
(since C++23) |
|
[ captures ] requires(optional) ( params ) lambda-specifiers requires(optional) { body } |
(3) |
(since C++20) |
|
[ captures ] requires(optional) { body } |
(4) |
(since C++20) (until C++23) |
|
[ captures ] requires(optional) lambda-specifiers { body } |
(4) |
(since C++23) |
- 完整声明。
- 省去参数列表:函数没有参数,就如同只有括号的调用形式().
- 与1相同,泛型语法需要显示提供参数列表
- 与2相同,并显式提供模板参数列表。
例子
// generic lambda, operator() is a template with two parameters
auto glambda = [](auto a, auto&& b) { return a < b; };
bool b = glambda(3, 3.14); // ok
// generic lambda, operator() is a template with one parameter
auto vglambda = [](auto printer) {
return [=](auto&&… ts) // generic lambda, ts is a parameter pack
{
printer(std::forward<decltype(ts)>(ts)…);
return [=] { printer(ts…); }; // nullary lambda (takes no parameters)
};
};
auto p = vglambda([](auto v1, auto v2, auto v3) { std::cout << v1 << v2 << v3; });
auto q = p(1, ‘a’, 3.14); // outputs 1a3.14
q(); // outputs 1a3.14
lambda说明符
|
lambda-specifiers |
– |
consists of specifiers, exception, attr and trailing-return-type in order, every component is optional |
|
specifiers |
– |
说明符的可选项。如未提供,则复制捕获的对象是lambda主体中的常量。允许使用以下说明符: |
|
exception |
– |
提供 dynamic exception specification (动态异常规范)或者 (C++20之前) 对于闭包()使用[noexcept说明符] |
|
attr |
– |
给函数调用运算符的类型或闭包类型的运算符模板提供[属性规范]。这样指定的任何属性都不属于函数调用运算符或运算符模板本身,而是属于其类型。(例如, 不能使用 [[noreturn]] 属性.) |
|
trailing-return-type |
– |
->ret,其中ret指定返回类型。如果尾部返回类型不存在,则闭包运算符()的返回类型将从返回语句中推导出来,就像其返回类型声明为auto的函数一样。 |
|
requires |
– |
(since C++20) 向闭包类型的运算符()添加约束 |
Lambda capture
captures是一个逗号分隔的列表,包含零个或多个captures,可以选择以capture default开头。捕获列表定义可从lambda函数体中访问的外部变量。唯一的捕获默认值是:
- & (通过引用隐式捕获使用的自动变量) 和
- = (通过复制隐式捕获使用的自动变量).
如果存在捕获默认值,则可以隐式捕获当前对象(this)。如果隐式捕获,则始终通过引用捕获,即使捕获默认值为=。当捕获默认值为“=”时,this的隐式捕获已被弃用. (since C++20)
单个捕获的语法为
|
identifier |
(1) |
|
|
identifier … |
(2) |
|
|
identifier initializer |
(3) |
(since C++14) |
|
& identifier |
(4) |
|
|
& identifier … |
(5) |
|
|
& identifier initializer |
(6) |
(since C++14) |
|
this |
(7) |
|
|
* this |
(8) |
(since C++17) |
|
… identifier initializer |
(9) |
(since C++20) |
|
& … identifier initializer |
(10) |
(since C++20) |
- 简单的拷贝捕获
- 简单的拷贝捕获,即 pack expansion
- 通过使用initializer进行副本捕获
- 简单引用捕获
- 简单的引用捕获,即pack expansion
- 使用初始值设定项通过引用捕获
- 当前对象的简单引用捕获
- 通过当前对象的拷贝捕获实现简单
- 通过使用作为包扩展的初始值设定项进行拷贝捕获
- 使用作为包扩展的初始值设定项进行引用捕获
例子
#include <vector>
#include <iostream>
#include <algorithm>
#include <functional>
int main()
{
std::vector<int> c = {1, 2, 3, 4, 5, 6, 7};
int x = 5;
c.erase(std::remove_if(c.begin(), c.end(), [x](int n) { return n < x; }), c.end());
std::cout << “c: “;
std::for_each(c.begin(), c.end(), [](int i){ std::cout << i << ‘ ‘; });
std::cout << ‘\n’;
// the type of a closure cannot be named, but can be inferred with auto
// since C++14, lambda could own default arguments
auto func1 = [](int i = 6) { return i + 4; };
std::cout << “func1: ” << func1() << ‘\n’;
// like all callable objects, closures can be captured in std::function
// (this may incur unnecessary overhead)
std::function<int(int)> func2 = [](int i) { return i + 4; };
std::cout << “func2: ” << func2(6) << ‘\n’;
std::cout << “Emulate `recursive lambda` calls:\nFibonacci numbers: “;
auto nth_fibonacci = [](int n) {
std::function<int(int,int,int)> fib = [&](int a, int b, int n) {
return n ? fib(a + b, a, n – 1) : b;
};
return fib(1, 0, n);
};
for (int i{1}; i != 9; ++i) { std::cout << nth_fibonacci(i) << “, “; }
std::cout << “\nAlternative approach to lambda recursion:\nFibonacci numbers: “;
auto nth_fibonacci2 = [](int n) {
auto fib = [](auto self, int a, int b, int n) -> int {
return n ? self(self, a + b, a, n – 1) : b;
};
return fib(fib, 1, 0, n);
};
for (int i{1}; i != 9; ++i) { std::cout << nth_fibonacci2(i) << “, “; }
}
输出如下:
c: 5 6 7
func1: 10
func2: 10
Emulate `recursive lambda` calls:
Fibonacci numbers: 1, 1, 2, 3, 5, 8, 13, 21,
Alternative approach to lambda recursion:
Fibonacci numbers: 1, 1, 2, 3, 5, 8, 13, 21,
异常处理
程序不是孤立存在的,他们都或多或少的依赖于外部工具。任何运行的进程,都会遇到错误,这些潜在的问题或错误,就是异常。再完美的代码,也会遇到错误和异常。因此,编写的程序,都需要认真做好错误处理。
抛出异常,使用throw关键字,可以抛出exception类型的异常,也可以抛出简单的int,或char*类型的简单类型;但是不建议这一使用,虽然c++没有明确禁止。
旧版本c++,允许指定函数或方法可抛出的异常列表(抛出列表,或异常规范),自c++11以后,已经不赞成使用他们了,c++17版本后,明确不在支持异常规范。但是throw()和noexcept还保留着。
异常规范语法举例:
void ReadFile(string_view fileName)
throw(invalid_argument, runtime_error) // exception specification, or exception list
{
// some code
}
c++标准的异常体系
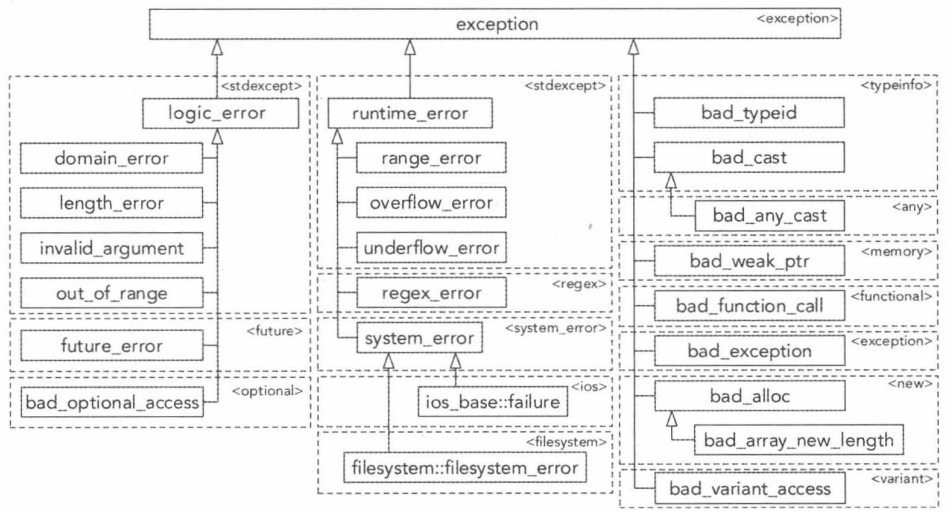

c++标准库中的所有异常都是这个层次结构中类的对象。这一些列类,都有what方法,它返回const char*字符串(错误信息)。exception是基类,可以在catch语句中可以使用它。
try
{
ReadFile(“somefile”);
}
catch( const invalid_argument & e )
{
// take some special action for invalid filenames.
}
catch( const exception & e )
{
cerr << e.what() << endl;
}
注意,在捕获异常时,一定要按引用捕获,如果按值捕获,就可能会发生截断,在此情况下将会丢失对象的信息。另外,当使用多条catch语句时,会按代码中的顺序匹配catch子句,字句应该按逐步扩大的顺序出现。应用运行的程序都至少有一个线程,当一个线程发生异常时,该线程应该负责捕获这个异常,其他线程无法捕获;当一个线程抛出的异常不能被捕获时,c++运行库将调用std::terminate(),从而终止整个应用程序。
我们可以编写自己的异常类库。自己编写的异常类,需要实现移动构造函数或复制构造函数,移动或复制被抛出的异常对象。自己编写的异常类,需要编写析构函数、赋值构造、复制预算符和移动构造与移动复制运算符。异常可能会被复制多次(按值捕获异常才会如此)。catch时,按引用捕获异常对象,可避免不必要的复制。
重新抛出异常
可使用throw关键字,重新抛出异常,如:
void g() { throw invalid_argument(“some arguments are error.”); }
void f()
{
try
{
g();
}
catch(const invalid_argument & e)
{
throw; // rethrow
}
}
int main()
{
try
{
f();
}
catch(const exception & e)
{
cerr << e.what() << endl;
}
return 0;
}
注意,不要使用throw e;这样的语句重新抛出异常,因为那样可能会截断异常对象。比如修改上面的代码
void f()
{
try
{
g();
}
catch(const exception & e)
{
//throw; // rethrow right
throw e;
}
}
int main()
{
try
{
f();
}
catch(const invalid_argument & e)
{
cerr << “invalid argument : ” << e.what() << endl;
}
catch(const exception & e)
{
cerr << “some error : ” << e.what() << endl;
}
return 0;
}
此时,main函数输出的是“some error”这个catch的内容,因为f中throw了基类的对象。记住,始终使用throw;来重新抛出异常对象。
堆栈的释放与清理
当某段代码抛出一个异常时,会在堆栈中寻找catch处理程序。当发现catch处理程序时,堆栈会释放所有中间堆栈帧,直接跳到定义catch处理程序的堆栈层。堆栈释放(stack unwinding)意味着调用所有具有局部作用域名称的析构函数;并忽略在当前执行点之前的每个函数中的所有代码。
粗心的异常处理会导致内存和资源的泄漏。可使用智能指针。对使用重要资源的函数,可以针对这些函数,捕获可能抛出的所有异常,执行必要的清理,并重新抛出异常,供堆栈中更高层函数做处理。
常见的错误处理程序
内存分配失败
c++允许指定new handler回调函数,如handler1。默认情况下,不存在这个handler1。如果存在的话,当内存分配失败时,内存分配例程会调用handler1,而不抛出异常。当然如果handler1返回后,再次尝试分配内存,仍然失败的话,例程还是调用handler1,要防止这样的情况发生。可以在handler1里,设置另一个函数handler2或抛出异常(bad_alloc异常派生类),用于处理无限循环的问题。
一般在handler1里面,会尝试释放一些内存,用于内存分配例程再次尝试分配内存。提供空间的技巧时,在应用程序启动时,提前雪藏一大块内存。而在handler1这里,释放这块内存。当然,在handler1里面还可以,在释放内存块后,采取保存文档,重启程序等一些列安全措施。
析构函数
- 析构函数,隐式标记为noexcept。如果带noexcept标记的析构函数抛出了一个异常的话,c++运行时会调用std::terminate函数来终止引用程序。在析构函数中,应该小心捕获可能发生的任何异常。
构造函数
如果异常离开了构造函数,将永远不会调用对象的析构函数。如果存在继承关系,那么基类的构造函数,将在派生类的构造函数调用前运行,如果派生类构造函数抛出了一个异常,那么c++会运行任何已经构建完整的基类的析构函数。
构造函数的function-try-blocks写法
class InnerClass
{
public:
InnerClass(int i)
{
throw std::runtime_error(“Exception by InnerClass ctor”); // 构造函数引发异常
}
}
class MyClass
{
public:
MyClass()
try
//:<ctor-initializer> 初始化列表
: ptr(new int[12]{1,2,89}), myInner(10)
{
// 构造函数体
}
catch(const exception &e)
{
// 异常处理;处理完后,必须重新抛出异常;如果没有这样做,运行时,将会重新抛出当前异常
// catch语句可以访问传递给构造函数的参数
// 在catch语句捕获异常后,构造函数已经构建的对象,都会在执行catch语句之前销毁。因此,
// 不要在catch语句内访问对象成员变量。当然如果有裸指针,则需要在catch语句中释放他们。
auto p = ptr;
ptr = nullptr;
delete[] p;
throw ;
}
private:
int * ptr = nullptr;
InnerClass myInner;
}
注意,一般仅将裸指针作为数据成员时,并且,在构造函数中,申请了这块内存,才有必要使用function-try-blocks。
运算符重载
c++可以重载的操作符有:二元算术运算符,一元算术运算符,位运算符,++/–,复制运算符,比较运算符,IO流运算符,布尔运算符,下标运算符,函数调用运算符,类型转换运算符,内存分配运算符,取地址运算符,解除引用运算符,解除引用指针-成员,逗号运算符等。
- 注意运算符重载,有方法或全局函数之分;大部分运算符既可以为方法,又可以为全局函数,但是,强烈建议先声明为方法,如果出错再定义为全局函数。因为方法可以是虚函数,还可以在继承中被重载;并且如果不修改对象数据的情况下,还可以被声明为const方法。不过,有些运算符,比如=,职能是方法,因为‘=’与类型绑定紧密;'<<‘和’>>’只能是全局函数(当运算符左侧的变量是除了自定义类型之外的任何类型的话,必须将这个运算符定义为全局的,比如<<左侧类型是iostream对象,而不是自定义类型)。
- 对于一些运算符,尽量不要尝试重载,尽管是可以重载的,比如取地址运算符(operator&),二元布尔运算符operator&&和operator||(可能会使短路求值规则失败),逗号运算符(序列运算符,sequence operator,分隔一条语句中的两个表达式,确保求职顺序从左到右)。
- 运算符重载,要仔细斟酌参数和返回值,到底是引用还是值,还要考虑右值类型的重载。
new/delete 重载
new在完成对象空间分配的工作之外,还要调用该对象的构造函数;delete也有类似的行为,先调用析构函数,再释放空间。一些内存池,会使用重载的new和delete,以便在不释放内存的情况下重用内存。c++标准指出,从delete抛出异常的行为是未定义的。所有delete永远都不应该抛出异常,因此operator delete的声明都是noexcept的。
语法形式
https://en.cppreference.com/w/cpp/memory/new/operator_new
https://en.cppreference.com/w/cpp/memory/new/operator_delete
摘取一段代码如下:
#include <cstdio>
#include <cstdlib>
#include <new>
// replacement of a minimal set of functions:
void* operator new(std::size_t sz) // no inline, required by [replacement.functions]/3
{
std::printf(“global op new called, size = %zu\n”, sz);
if (sz == 0)
++sz; // avoid std::malloc(0) which may return nullptr on success
if (void *ptr = std::malloc(sz))
return ptr;
throw std::bad_alloc{}; // required by [new.delete.single]/3
}
void operator delete(void* ptr) noexcept
{
std::puts(“global op delete called”);
std::free(ptr);
}
int main()
{
int* p1 = new int;
delete p1;
int* p2 = new int[10]; // guaranteed to call the replacement in C++11
delete[] p2;
}
多线程
c++98/03不支持多线程编程,必须借助第三方库或目标操作系统中的api。多线程编程中的难点是,不能将问题分解为并行执行的部分。一般的做法就是讲问题分解为部分可并行的,从而提升性能。
使用thread的例子
#include <thread>
#include <iostream>
using namespace std;
class Counter
{
public:
Counter(int id, int num)
:mId(id), mNum(num)
{}
void operator()() const
{
for(int i = 0; i < mNum; ++i)
{
cout << “Counter ” << mId <<” has value ” << i << endl;
}
}
private:
int mId;
int mNum;
}
class Request
{
public:
Request(int id):mId(id){
;
}
void process()
{
cout << “Processing request: ” << mId << endl;
}
private:
int mId;
}
void test()
{
thread t1{Counter{1,20}};
Counter c(2,12);
thread t2(ref(c));
thread t3(Counter(3,10));
int id = 4;
int num = 5;
thread t4([id, num]{
for(int i = 0; i < num; ++i){
cout << “Counter ” << id <<” has value ” << i << endl;
}
});
Request req(100);
thread t5{&Request::process, &req};
t1.join();
t2.join();
t3.join();
t4.join();
t5.join();
}
线程本地存储
thread_local 是一个存储器指定符。
所谓存储器指定符,其作用类似命名空间,指定了变量名的存储期以及链接方式。同类型的关键字还有:
- auto:自动存储期;
- register:自动存储期,提示编译器将此变量置于寄存器中;
- static:静态或线程存储期,同时提示是内部链接;
- extern:静态或线程存储期,同时提示是外部链接;
- thread_local:线程存储期;
- mutable:不影响存储期或链接。
对于 thread_local,官方解释是:
thread_local 关键词只对声明于命名空间作用域的对象、声明于块作用域的对象及静态数据成员允许。它指示对象拥有线程存储期。它能与 static 或 extern 结合,以分别指定内部或外部链接(除了静态数据成员始终拥有外部链接),但附加的 static 不影响存储期。
线程存储期: 对象的存储在线程开始时分配,而在线程结束时解分配。每个线程拥有其自身的对象实例。唯有声明为 thread_local 的对象拥有此存储期。 thread_local 能与 static 或 extern 一同出现,以调整链接。
这里有一个很重要的信息,就是 static thread_local 和 thread_local 声明是等价的,都是指定变量的周期是在线程内部,并且是静态的。这是什么意思呢?举个代码的例子。
全局变量
#include <iostream>
#include <thread>
#include <mutex>
std::mutex cout_mutex; //方便多线程打印
thread_local int x = 1;
void thread_func(const std::string& thread_name) {
for (int i = 0; i < 3; ++i) {
x++;
std::lock_guard<std::mutex> lock(cout_mutex);
std::cout << “thread[” << thread_name << “]: x = ” << x << std::endl;
}
return;
}
int main() {
std::thread t1(thread_func, “t1”);
std::thread t2(thread_func, “t2”);
t1.join();
t2.join();
return 0;
}
输出
thread[t2]: x = 2
thread[t2]: x = 3
thread[t2]: x = 4
thread[t1]: x = 2
thread[t1]: x = 3
thread[t1]: x = 4
局部变量
#include <iostream>
#include <thread>
#include <mutex>
std::mutex cout_mutex; //方便多线程打印
void thread_func(const std::string& thread_name) {
for (int i = 0; i < 3; ++i) {
thread_local int x = 1;
x++;
std::lock_guard<std::mutex> lock(cout_mutex);
std::cout << “thread[” << thread_name << “]: x = ” << x << std::endl;
}
return;
}
int main() {
std::thread t1(thread_func, “t1”);
std::thread t2(thread_func, “t2”);
t1.join();
t2.join();
return 0;
}
输出
thread[t2]: x = 2
thread[t2]: x = 3
thread[t2]: x = 4
thread[t1]: x = 2
thread[t1]: x = 3
thread[t1]: x = 4
可以看到虽然是局部变量,但是在每个线程的每次 for 循环中,使用的都是线程中的同一个变量,也侧面印证了 thread_local 变量会自动 static。还有thread_local 虽然改变了变量的存储周期,但是并没有改变变量的使用周期或者说作用域,比如上述的局部变量,其使用范围不能超过 for 循环外部,否则编译出错。
类对象
#include <iostream>
#include <thread>
#include <mutex>
std::mutex cout_mutex;
//定义类
class A {
public:
A() {
std::lock_guard<std::mutex> lock(cout_mutex);
std::cout << “create A” << std::endl;
}
~A() {
std::lock_guard<std::mutex> lock(cout_mutex);
std::cout << “destroy A” << std::endl;
}
int counter = 0;
int get_value() {
return counter++;
}
};
void thread_func(const std::string& thread_name) {
for (int i = 0; i < 3; ++i) {
thread_local A* a = new A();
std::lock_guard<std::mutex> lock(cout_mutex);
std::cout << “thread[” << thread_name << “]: a.counter:” << a->get_value() << std::endl;
}
return;
}
int main() {
std::thread t1(thread_func, “t1”);
std::thread t2(thread_func, “t2”);
t1.join();
t2.join();
return 0;
}
输出
create A
thread[t1]: a.counter:0
thread[t1]: a.counter:1
thread[t1]: a.counter:2
create A
thread[t2]: a.counter:0
thread[t2]: a.counter:1
thread[t2]: a.counter:2
虽然 createA() 看上去被调用了多次,实际上只被调用了一次,因为 thread_local 变量只会在每个线程最开始被调用的时候进行初始化,并且只会被初始化一次。当然如果是赋值,那就不一样了。
thread_local声明类成员时,必须声明为static。
class B {
public:
B() {
std::lock_guard<std::mutex> lock(cout_mutex);
std::cout << “create B” << std::endl;
}
~B() {}
thread_local static int b_key;
//thread_local int b_key;
int b_value = 24;
static int b_static;
};
thread_local int B::b_key = 12;
int B::b_static = 36;
void thread_func(const std::string& thread_name) {
B b;
for (int i = 0; i < 3; ++i) {
b.b_key–;
b.b_value–;
b.b_static–; // not thread safe
std::lock_guard<std::mutex> lock(cout_mutex);
std::cout << “thread[” << thread_name << “]: b_key:” << b.b_key << “, b_value:” << b.b_value << “, b_static:” << b.b_static << std::endl;
std::cout << “thread[” << thread_name << “]: B::key:” << B::b_key << “, b_value:” << b.b_value << “, b_static: ” << B::b_static << std::endl;
return;
}
输出
create B
thread[t2]: b_key:11, b_value:23, b_static:35
thread[t2]: B::key:11, b_value:23, b_static: 35
thread[t2]: b_key:10, b_value:22, b_static:34
thread[t2]: B::key:10, b_value:22, b_static: 34
thread[t2]: b_key:9, b_value:21, b_static:33
thread[t2]: B::key:9, b_value:21, b_static: 33
create B
thread[t1]: b_key:11, b_value:23, b_static:32
thread[t1]: B::key:11, b_value:23, b_static: 32
thread[t1]: b_key:10, b_value:22, b_static:31
thread[t1]: B::key:10, b_value:22, b_static: 31
thread[t1]: b_key:9, b_value:21, b_static:30
thread[t1]: B::key:9, b_value:21, b_static: 30
原子操作
使用atomic库可以对整形数据提供无锁操作。不过,某些类型的原子操作,底层可能是使用了同步机制实现的(如底层目标硬件不支持原子操作的指令)。可在原子类型上使用is_lock_free()来查询释放支持无锁操作。可将atomic类模板与所有类型一起使用,并非仅限于整数类型。atomic类模板,要求类型,具备is_trivially_copy特点。底层是否需要同步机制,取决于该类型的大小。
互斥
互斥体(非定时,定时):mutex,recursive_mutex,shared_mutex,timed_mutex,recursive_timed_mutex,shared_timed_mutex。非定时的互斥体方法:lock(),try_lock(),unlock();定时的互斥体方法:try_lock_for(chrono::duration),try_lock_until(chrono::time_point)。已经获得了timed_mutex或shared_timed_mutex所有权的线程,不得再次获取这个互斥体上的锁,否则会导致死锁。
锁:lock_guard,unique_lock,shared_lock,scoped_lock(可接收多个数量可变的互斥体)。
call_once和once_flag组合,可以保证某个函数或方法只调用一次。可以用来实现不需要双重检查锁定模式的单例。
#pragma once
// JamboMa 2021-2-2
#include <mutex>
#include <thread>
using namespace std;
template<typename T>
struct SingleTon
{
public:
static T* get()
{
static T* p{ nullptr };
call_once(flag, [&]()->void {
p = new T();
});
return p;
}
T* operator->() const {
return get();
}
SingleTon() {}
SingleTon(const SingleTon&) = delete;
SingleTon& operator=(const SingleTon&) = delete;
private:
static once_flag flag;
};
template<typename T> once_flag SingleTon<T>::flag;
使用定时锁
class Counter
{
public:
Counter(int id, int num)
:mId(id), mNum(num)
{
;
}
void operator()()const
{
for(int i = 0; i < mNum; ++i)
{
unique_lock lock(sTimedMutex, 200ms);
if(lock){
cout << “Counter ” << mId << ” has value ” << i << endl;
}
else{
// skip output when time out
}
}
}
private:
int mId;
int mNum;
static time_mutex sTimedMutex;
}
timed_mutex Counter::sTimedMutex;
条件变量
条件变量允许一个线程阻塞,直到另一个线程设置某个条件或者系统时间到达某个指定的时间。有两个条件变量,condition_variable和condition_ variable_any。condition_variable只等待unique_lock上的条件变量;condition_ variable_any可等待任何对象的条件变量,包括自定义的锁类型。用法,就是一个线程wait,另一个线程可以notify_one/notify_all来唤醒wait的线程。
template<typename T>
class ConsumeQueue<T>
{
private :
queue<T> msgQueue;
condition_variable mCondVar;
mutex mMutex;
public:
void Enqueue(const T & data)
{
unique_lock lock(mMutex);
msgQueue.push(data);
mCondVar.notify_all();
}
bool DequeueOne(T & one, chrono::milliseconds ms)
{
unique_lock(mMutex);
if(mCondVar.wait_for(lock, ms, [this]{return !msgQueue.empty();}))
{
one = msgQueue.front();
msgQueue.pop();
return true;
}
return false;
}
}
future
promise和future
在promise上可以设置某个值或异常;另外的线程可以通过future取出这个数值。
#include <vector>
#include <thread>
#include <future>
#include <numeric>
#include <iostream>
#include <chrono>
void accumulate(std::vector<int>::iterator first,
std::vector<int>::iterator last,
std::promise<int> accumulate_promise)
{
int sum = std::accumulate(first, last, 0);
accumulate_promise.set_value(sum); // Notify future
}
void do_work(std::promise<void> barrier)
{
std::this_thread::sleep_for(std::chrono::seconds(1));
barrier.set_value();
}
int main()
{
// Demonstrate using promise<int> to transmit a result between threads.
std::vector<int> numbers = { 1, 2, 3, 4, 5, 6 };
std::promise<int> accumulate_promise;
std::future<int> accumulate_future = accumulate_promise.get_future();
std::thread work_thread(accumulate, numbers.begin(), numbers.end(),
std::move(accumulate_promise));
// future::get() will wait until the future has a valid result and retrieves it.
// Calling wait() before get() is not needed
//accumulate_future.wait(); // wait for result
std::cout << “result=” << accumulate_future.get() << ‘\n’;
work_thread.join(); // wait for thread completion
// Demonstrate using promise<void> to signal state between threads.
std::promise<void> barrier;
std::future<void> barrier_future = barrier.get_future();
std::thread new_work_thread(do_work, std::move(barrier));
barrier_future.wait();
new_work_thread.join();
}
packaged_task
packaged_task可以方便的使用promise。它包装任何可调用的目标(函数、lambda表达式、绑定表达式或其他函数对象),以便可以异步调用它。它的返回值或抛出的异常存储在共享状态中,可以通过std::future对象访问该状态。
#include <iostream>
#include <cmath>
#include <thread>
#include <future>
#include <functional>
// unique function to avoid disambiguating the std::pow overload set
int f(int x, int y) { return std::pow(x,y); }
void task_lambda()
{
std::packaged_task<int(int,int)> task([](int a, int b) {
return std::pow(a, b);
});
std::future<int> result = task.get_future();
task(2, 9);
std::cout << “task_lambda:\t” << result.get() << ‘\n’;
}
void task_bind()
{
std::packaged_task<int()> task(std::bind(f, 2, 11));
std::future<int> result = task.get_future();
task();
std::cout << “task_bind:\t” << result.get() << ‘\n’;
}
void task_thread()
{
std::packaged_task<int(int,int)> task(f);
std::future<int> result = task.get_future();
std::thread task_td(std::move(task), 2, 10);
task_td.join();
std::cout << “task_thread:\t” << result.get() << ‘\n’;
}
int main()
{
task_lambda();
task_bind();
task_thread();
}
// 输出如下
task_lambda: 512
task_bind: 2048
task_thread: 1024
async
它的目的就是要c++运行时控制,是否创建一个线程来进行某种计算,并可返回用于检索结果的future。async通过两种方法运行函数:创建一个新线程,异步运行提供的函数;或在返回的future上调用get()方法时,在主调线程上同步运行函数。可以默认让c++运行时或手动设置上述两种方式。具体:launch::async,强制c++运行时在一个不同的线程上异步运行函数;launch::defered,强制c++运行时在调用get()时,在主调用线程上同步的执行函数。
调用async()锁返回的future,会在其析构函数中阻塞,直到结果可用为止。这意味着如果调用async()时,未捕获返回的future,async()调用将真正成为阻塞调用。
future的好处是会自动在线程之间传递异常。在future上调用get()时,要么返回结果,要么重新抛出存储于promise中的异常。也就是说在调用future.get()时,需要用到try-catch。
shared_future
future在调用get()后,将结果移出future,传递给调用者。这意味着,future.get()只能被调用一次。如果要调用多次,则需要使用shared_future。用法是:future::share();或给shared_future构造函数传递future。这就意味着,shared_future可以唤醒多个线程(可用于线程池)。
#include <iostream>
#include <future>
#include <chrono>
int main()
{
std::promise<void> ready_promise, t1_ready_promise, t2_ready_promise;
std::shared_future<void> ready_future(ready_promise.get_future());
std::chrono::time_point<std::chrono::high_resolution_clock> start;
auto fun1 = [&, ready_future]() -> std::chrono::duration<double, std::milli>
{
t1_ready_promise.set_value();
ready_future.wait(); // waits for the signal from main()
return std::chrono::high_resolution_clock::now() – start;
};
auto fun2 = [&, ready_future]() -> std::chrono::duration<double, std::milli>
{
t2_ready_promise.set_value();
ready_future.wait(); // waits for the signal from main()
return std::chrono::high_resolution_clock::now() – start;
};
auto fut1 = t1_ready_promise.get_future();
auto fut2 = t2_ready_promise.get_future();
auto result1 = std::async(std::launch::async, fun1);
auto result2 = std::async(std::launch::async, fun2);
// wait for the threads to become ready
fut1.wait();
fut2.wait();
// the threads are ready, start the clock
start = std::chrono::high_resolution_clock::now();
// signal the threads to go
ready_promise.set_value();
std::cout << “Thread 1 received the signal ”
<< result1.get().count() << ” ms after start\n”
<< “Thread 2 received the signal ”
<< result2.get().count() << ” ms after start\n”;
}
线程池与并行计算
可以使用Intel Threading Building Blocks(TBB)和Microsoft Parallel Patterns Library(PPL)。简单的线程池,就是创建一系列的线程(线程数量跟硬件有关系),并调度他们完成各种任务。大多数情况下,线程的理想数量应该与处理器核心数目(thread::hardware_concurrency())相同,但是这种情况适用于计算密集型线程,不能用于其他容易阻塞的线程,如IO。当线程可以阻塞时,往往运行数目多于核心数目,会更合适。
threadpool 示例
#ifndef THREAD_POOL_H
#define THREAD_POOL_H
#include <vector>
#include <queue>
#include <atomic>
#include <future>
//#include <condition_variable>
//#include <thread>
//#include <functional>
#include <stdexcept>
namespace std
{
//线程池最大容量,应尽量设小一点
#define THREADPOOL_MAX_NUM 16
//#define THREADPOOL_AUTO_GROW
//线程池,可以提交变参函数或拉姆达表达式的匿名函数执行,可以获取执行返回值
//不直接支持类成员函数, 支持类静态成员函数或全局函数,Opteron()函数等
class threadpool
{
using Task = function<void()>; //定义类型
vector<thread> _pool; //线程池
queue<Task> _tasks; //任务队列
mutex _lock; //同步
condition_variable _task_cv; //条件阻塞
atomic<bool> _run{ true }; //线程池是否执行
atomic<int> _idlThrNum{ 0 }; //空闲线程数量
public:
inline threadpool(unsigned short size = 4) { addThread(size); }
inline ~threadpool()
{
_run=false;
_task_cv.notify_all(); // 唤醒所有线程执行
for (thread& thread : _pool) {
//thread.detach(); // 让线程“自生自灭”
if(thread.joinable())
thread.join(); // 等待任务结束, 前提:线程一定会执行完
}
}
public:
// 提交一个任务
// 调用.get()获取返回值会等待任务执行完,获取返回值
// 有两种方法可以实现调用类成员,
// 一种是使用 bind: .commit(std::bind(&Dog::sayHello, &dog));
// 一种是用 mem_fn: .commit(std::mem_fn(&Dog::sayHello), this)
template<class F, class… Args>
auto commit(F&& f, Args&&… args) ->future<decltype(f(args…))>
{
if (!_run) // stoped ??
throw runtime_error(“commit on ThreadPool is stopped.”);
using RetType = decltype(f(args…)); // typename std::result_of<F(Args…)>::type, 函数 f 的返回值类型
auto task = make_shared<packaged_task<RetType()>>(
bind(forward<F>(f), forward<Args>(args)…)
); // 把函数入口及参数,打包(绑定)
future<RetType> future = task->get_future();
{ // 添加任务到队列
lock_guard<mutex> lock{ _lock };//对当前块的语句加锁 lock_guard 是 mutex 的 stack 封装类,构造的时候 lock(),析构的时候 unlock()
_tasks.emplace([task](){ // push(Task{…}) 放到队列后面
(*task)();
});
}
#ifdef THREADPOOL_AUTO_GROW
if (_idlThrNum < 1 && _pool.size() < THREADPOOL_MAX_NUM)
addThread(1);
#endif // !THREADPOOL_AUTO_GROW
_task_cv.notify_one(); // 唤醒一个线程执行
return future;
}
//空闲线程数量
int idlCount() { return _idlThrNum; }
//线程数量
int thrCount() { return _pool.size(); }
#ifndef THREADPOOL_AUTO_GROW
private:
#endif // !THREADPOOL_AUTO_GROW
//添加指定数量的线程
void addThread(unsigned short size)
{
for (; _pool.size() < THREADPOOL_MAX_NUM && size > 0; –size)
{ //增加线程数量,但不超过 预定义数量 THREADPOOL_MAX_NUM
_pool.emplace_back( [this]{ //工作线程函数
while (_run)
{
Task task; // 获取一个待执行的 task
{
// unique_lock 相比 lock_guard 的好处是:可以随时 unlock() 和 lock()
unique_lock<mutex> lock{ _lock };
_task_cv.wait(lock, [this]{
return !_run || !_tasks.empty();
}); // wait 直到有 task
if (!_run && _tasks.empty())
return;
task = move(_tasks.front()); // 按先进先出从队列取一个 task
_tasks.pop();
}
_idlThrNum–;
task();//执行任务
_idlThrNum++;
}
});
_idlThrNum++;
}
}
};
}
#endif //https://github.com/lzpong/
跨平台
C++语言会遇到平台问题,原因是多方面的。C++是一门高级语言,C++标准并未指定某些低级细节。例如, C++标准并未定义内存中对象的布局,而留给编译器去处理。不同编译器可为对象使用不同的内存布局。C++ 面临的另一个挑战是:提供标准语言和标准库,却没有标准实现。C++编译器和库供应商对规范有不同解释, 当从一个系统迁移到另一个系统时,会导致问题。最后,C++在语言所提供的标准中是有选择性的。尽管存在 标准库,但程序经常需要并非由C++语言或标准库提供的功能;功能通常来自第三方库或平台,而且差异很大。
架构问题
术语“架构”通常指运行程序的一个或一系列处理器。运行Windows或Linux的标准PC通常运行在x86 或x64架构上,较旧的Mac OS版本通常运行在PowerPC架构上。作为一门高级语言,C++会向你隐藏这些架
构之间的区别。例如,Core i7处理器的一条指令可能与6条PowerPC指令执行相同的功能。作为一名C++程 序员,不需要了解这种差异,甚至不必知道存在这种差异。使用高级语言的一个优点在于由编译器负责将代码 转换为处理器的本地汇编代码格式。
1.整数大小
C++标准并未定义整数类型的准确大小。C++标准仅指出:
有5种标准的有符号整数类型:signed char, short int. int、long int和1 ong long into在这个列表中,后一 种类型占用的存储空间大于或等于前一种类型。
C++标准的确进一步说明了这些类型的大小,但从未给出确切大小。实际大小取决于编译器。因此,如果 要编写跨平台代码,就不能盲目地依赖这些类型。
如果要编写跨平•台代码,建议用<cstdint>类型替代基本整数类型。
2.二进制兼容性
你可能巳经知道,为Corei7计算机编写和编译的程序不能在基于PowerPC的Mac上运行。这两个平台无 法实现二进制兼容性,因为处理器支持的不是同一组指令。在编译C++程序时,源代码将转换为计算机执行的 二进制指令。二进制格式由平台(而非C++语言)定义。
为支持不具备二进制兼容性的平台,一种解决方案是在每个目标平台上使用编译器分别构建每个版本。
另一种解决方案是交叉编译(cross-compiling)o如果为开发使用平台X,但想使程序运行在平台Y和Z上, 可在平台X上使用交叉编译器,为平台Y和Z生成二进制代码。
也可以使自己的程序成为开源程序。如果最终用户可得到源代码,则可在用户自己的系统上对源代码进行 本地编译,针对本地计算机构建具有正确二进制格式的程序版本。开源软件已经日益流行,一 个主要原因是它们允许程序员协作开发软件,并增加可运行程序的平台数量。
3.地址大小
当提到架构是32位时,通常是说地址大小是32位或4字节。通常而言,具有更大地址大小的系统可处理 更多内存,在复杂系统上的运行速度更快。在64位平台上,指针是64位,但整数可能是32位。将64位指 针强制转换为32位整数时,将丢失32个关键位! C++标准在vcstdint>中定义了 std::intptr_t整数类型,它的大 小至少足以存储一个指针。根据C++标准,这种类型的定义是可选的,但几乎所有编译器都支持它。
警告:
不要认为指针一定是32位或4字节。除非使用std::intptr_t,否则不要将指针强制转换为整数。
4.字节顺序
所有现代计算机都以二进制形式存储数字,但同一个数字在两个平台上的表示形式可能不同。这听起来是 矛盾的,但可以看到,可通过两种合理方法来读取数字。一种表示数字的方式是将高位字节首先放入内存,接着将低位字节放入内存。这种策略被称为大端序,如PowerPC和SPARC处理器使用大端序。其他一些处理器(如x86)按相反顺序放置 字节,首先将低序字节放入内存。这种策略被称为小端序,因为数字的较小部分首先放置。网络上的字节序,是使用大端序。
实现问题
1.编译器的处理和扩展
在编写C++编译器时,编写者尝试遵循C++标准。但是,C++标准的长度超过1000页,包含刻板的论述、 语言语法和示例。即使两个人都按这个标准实现编译器,也不大可能以相同的方式解读预先规定的信息中的每 一部分,也无法顾及每种边缘情况。并不存在查找或避免编译器bug的简单方法。最好的做法是一直保持编译器的版本是最新的,也可能需要 订阅编译器的邮件列表或新闻组。
如果怀疑自己遇到了编译器bug,可以在网上简单地搜索自己看到的错误消息或条件,尝试找到变通方法 或补丁。
众所周知,编译器存在的一个重要问题是难以跟上C++标准最新添加或更新的语言功能。不过近几年,几 个主流编译器的供应商已能较快地为最新功能添加支持。
需要了解的另一个问题是,编译器经常包含程序员注意不到的独特语言扩展。例如,VLA(Variable-Length stack-based Array,基于变长栈的数组)并非C++语言的一部分,而是C语言的一部分。有些编译器既支持C标 准,又支持C++标准,允许在C++代码中使用VLA g++就是这样一种编译器。在g++编译器中,以下代码可 以如期编译和运行:
int i = 4;
char myStackArray[i]; // Not a standard language feature!
一些编译器扩展是有用的,但如果在某个时间点有机会切换编译器,可以看一下编译器是否有Strict模式; 在该模式下,会避免使用此类扩展。例如,若将-pedantic标志传给g++来编译上面的代码,将看到以下警告 消息:
warning: ISO C++ forbids variable length array ‘myStackArray* [-Wvla]
C++规范允许由编译器定义的某些类型的语言扩展,这是通过#pragma机制实现的。#pragma是一条预处理 指令,其行为由实现定义。如果实现不理解该指令,则会忽略它。例如,一些编译器允许程序员使用#pragma 临时关闭编译器警告。
2.库实现
编译器很可能包含C++标准库的实现。由于标准库用C++编写,因此并非必须使用与编译器打包在一起的 实现。可以使用经过性能优化的第三方标准库。
当然,标准库实现面临着与编译器编写者同样的问题:同一个C++标准,不同的解读。另外,对某些实现 可能进行了一些权衡,不符合需要。例如,一种实现是针对性能优化的,而另一种实现重点关注尽量减少为容 器使用的内存。
在使用标准库实现或任何第三方库时,必须考虑设计者在开发期间所做的权衡。
3.平台专用功能
C++是卓越的通用语言,又添加了标准库,包含的功能十分丰富;对于业余程序员来说,甚至可以多年仅 凭借C++的内置功能来轻松地编写C++代码。但是,专业程序员需要一些C++未提供的工具。本节将列出一些 由平台或第三方库(而非由C++语言或C++标准库)提供的重要功能。
•图形用户界面:当今,运行在操作系统上的大多数商业程序都有图形用户界面,其中包含诸多元素, 如可单击按钮、可移动窗口和级联菜单。与C语言类feL C++不存在这些元素的概念。要在C++中编 写图形应用程序,可使用平台专用的库来绘制窗口、接收鼠标输入以及执行其他图形任务。更好的选 择是使用第三方库,如wxWidgets或Qt,这些库为构建图形应用程序提供了抽象层。这些库经常支持 许多不同的目标平台。
•联网:Internet己经改变了我们编写应用程序的方式。当今,大多数应用程序都通过Web检查更新,游戏会通过网络提供多玩家模式。C++尚未提供联网机制,但存在几个标准库。使用抽象的套接字(socket) 来编写联网软件是最常用的方式。大多数平台都包含套接字实现,允许釆用简单的面向过程的方式在 网络上传输数据。一些平台支持基于流的网络系统,运行方式类似于C++中的I/O流。还有可用的第三 方网络库提供了网络抽象层。这些库通常支持多个不同的目标平台。IPv6正日益流行开来。因此,不要选择仅支持IPv4的网络库,最好选择独立于IP版本的网络库。
• OS事件和应用程序交互:在纯粹的C++代码中,与周边的操作系统以及其他应用程序的交互极少。在 没有平台扩展的标准C++程序中,只会接触命令行参数。C++不直接支持诸如复制和粘贴的操作。可以 使用平台提供的库,也可以使用支持多平台的第三方库。例如,wxWidgets和Qt库都抽象了复制和粘贴操作,并且支持多个平台。
•低级文件:第13章解释了 C++中的标准I/O,包括读写文件。许多操作系统都提供自己的文件API,通 常与C++中的标准文件类兼容。这些库通常提供OS专用文件工具,如获取当前用户主目录的机制。
•线程:C++03及更早版本不直接支持在单个程序中执行并发线程。从C++11开始,标准库添加了线程 支持库,如第23章所述;C++17己经添加了并行算法,如第18章所述。如果需要标准库以外更强大的线程功能,需要使用第三方库,如 Intel TBB(Threading Building Block)和 STE||AR Group HPX(High Performance ParalleX),OpenMP等。
跨语言开发
对于某些类型的程序而言,C++并非完成工作的最佳工具。例如,如果UNIX程序需要与shell环境密切交 互,则最好编写shell脚本而非C++程序。如果程序执行繁重的文本处理,你可能决定使用Perl语言。如果需 要大量的数据库交互,那么C#或Java是更好的选择。C#和WPF框架更适于编写现代的GUI应用程序。如果 决定使用另一种语言,有时可能想要调用C++代码,例如执行一些计算昂贵的操作。幸运的是,可使用一些工 具来取二者之长,将另一种语言的专长与C++的强大功能和灵活性结合起来。
c与c++混合编译链接
c++是C语言的超集,但是C里面没有C++语言的一些关键字(如class等),C支持VLA(Variable-Length Array,变长数组),而C++不支持。C++使用C实现的库时,可以使用facade模式。另外,C语言不支持重载,C编译器生成的名字也比较简单(C++存在名字分解/改编)。C++链接C库时,需要使用extern “language”限定
// extern “language’的语法如下:
extern “language” declaration1;
extern “language” declaration2;
//也可能如下:
extern “language” {
declaration1(); declaration2();
}
// 如
extern “C” void foo(int);
extern “C”
{
void g(char);
int i;
}
// 许多编译器只支持c;但实际上还应该有:
extern “Fortran” Matrixinvert(Matrix* M);
extern “Pascal” SomeLegacySubroutine(int n);
extern “Ada” AimMissileDefense(double angle);
使用extem的更常见模式是在头文件级别。例如,如果使用C语言编写的图形库,很可能带有供使用的.h 文件。可以编写另一个头文件,将原始文件打包到extern块中,以指定定义函数的整个头文件是用C编写的。 包装器的.h文件通常使用.hpp名称,从而与C版本的头文件区分开:
// graphicslib.hpp
extern “C” (
#include “graphicslib.h”
}
另一个常见模型是编写单个头文件,然后根据条件针对C或C++对其进行编译。如果为C++编译,C++编 译器将预定义_cplusplus符号。该符号不是为C编译定义的。因此,可以经常看到以下形式的头文件:
#ifdef cplusplus
extern “C” (
#endif
declaration1;
declaration2;
#ifdef cplusplus
} // matches extern “C”
#endif
这意味着declaration1和declaration2是C编译器编译的库中的函数。使用该技术,同一个头文件可同时 用于C和C++客户端。
C++与C#
假设正在使用C#开发诸如GUI的应用程序,但使用C++实现某些性能关键组件或 计算昂贵组件。为实现互操作,需要用C++编写一个库,这个库可从C#调用。在Windows上,库将会是.DLL 文件(so,for linux)。以下C++示例定义了 FunctionInDLL()函数,这个函数将编译为库。该函数接收一个Unicode字符串,并 返回一个整数。这个实现将收到的字符串写入控制台,并将值42返回给调用者:
#include <iostream>
using namespace std;
// windows 下可以
extern “C”
{
declspec(dllexport) int FunctionlnDLL(const wchar_t* p){
wcout « L”nThe following string was received by C++:” << endl;
wcout << p << endl;
return 42; // Return some value…
}
}
编译代码的方式取决于环境。如果正在 使用Microsoft Visual C++,那么需要定位项目属性,选择Dynamic Library(.dll)作为配置类型。注意,这个示例 使用_declspec(dllexport)告知链接器:这个函数应当供库的客户端使用。这是Microsoft Visual C++的处理方式。 其他链接器可能使用不同的机制来导出函数。一旦有了库,就可以使用互操作服务,从C#调用该库。首先需要添加InteropServices名称空间:
using System.Runtime.InteropServices;
接下来定义函数原型,并告知C#从何处查找函数的实现。可使用下面的代码行,假设己经将该库编译为 HelloCpp.dll:
[Dlllmport(“HelloCpp.dll”, CharSet = CharSet.Unicode)]
public static extern int FunctionlnDLL(String s);
代码行的第一部分告知C#:应当从HelloCpp.dll库导入该函数,而且应当使用Unicode字符串。第二部分 指定函数的实际原型,这个函数接收一个字特串参数,并返回整数。以下代码是一个完整的示例,演示了如何 从C#使用C++库:
using System;
using System.Runtime.InteropServices;
namespace HelloCSharp
{
class Program
{
[Dlllmport (“HelloCpp. dll*’, CharSet = CharSet. Unicode)]
public static extern int FunctionlnDLL(String s);
static void Main(string[] args)
{
Console.WriteLine (“Written by C#”);
int result = FunctionlnDLL (“Some string from C#.”);
Console.WriteLine (#34;C++ returned the value {result});
}
}
}
// 输出如下:
Written by C#.
The following string was received by C++:
‘Some string from C#.’
C++ returned the value 42
C++与Java
在Java中使用JNI调用C++代码。JNI(Java Native Interface, Java本地接口)是Java语言的一部分,允许程序员访问用Java之外的语言编写的 功能。JNI允许程序员使用通过其他语言(如C++)编写的库。如果Java程序员有性能关键或计算昂贵的代码段, 或需要使用遗留代码,可以访问C++库。也可以使用JNI在C++程序中执行Java代码,但这种用法极少见。
下面是个小例子,首先是java部分的代码
public class HelloCpp {
static {
System.loadLibrary(“hellocpp”);
}
// This will be implemented in C++.
public static native void callCpp();
public static void main(String[] args)
{
System.out.printIn(“Hello from Java!”);
callCpp();
}
}
这是Java一方需要完成的所有工作。现在,只需要像往常一样编译Java程序:
javac HelloCpp.java
然后使用javah程序,为本地方法创建头文件:
javah HelloCpp
运行javah后,将看到HelloCpp.h文件,这是一个完备(但有些简陋)的C/C++头文件。这个头文件中是 Java_HelloCpp_callCpp()函数的C函数定义。C++程序需要实现该函数。完整原型如下:
JNIEXPORT void JNICALL Java_HelloCpp_callCpp(JNIEnv*z jclass);
该函数的C++实现可充分利用C++语言。该例从C++输岀一些文本。首先,需要添加由javah创建的jni.h 和HelloCpp.h文件。还需要添加想要使用的任何C++头文件,然后像往常一样编写C++函数。函数的参数允许与Java环境以及称为本地代码的对象进行交互。cpp代码如下:
#include <jni.h>
#include “HelloCpp.h”
#include <iostream>
JNIEXPORT void JNICALL Java_HelloCpp_callCpp(JNIEnv*, jclass)
(
std::cout << “Hello from C++!” « std::endl;
}
要根据环境,将该代码编译为库,很可能需要调整编译器的设置以包含JNI头文件。在Linux上使用GCC 编译器,编译器命令如下所示:
g++ -shared -I/usr/java/jdk/include/ -I/usr/java/jdk/include/linux HelloCpp.cpp -o hellocpp.so
编译器的输出是Java程序使用的库。只要共享库在Java类路径的某个位置,就可以像往常一样执行Java
程序:
java HelloCpp
结果如下:
Hello from Java!
Hello from C++!
C++与Lua
编写高效的c++程序
编写高效的程序不仅要在设计层次深思熟虑,还涉及实现层次的细节。性能是程序生命周期一开始就要思考的问题。
高效的使用对象
通过应用传递
复杂对象应该尽可能通过引用向函数或方法传递,引用可以避免复制开销。如果函数必须修改对象,可通过引用传递对象;如果不修改参数对象,则通过const&传递参数对象。尽量不要用指针传递,按指针传递相对过时了。
按应用返回
正如应该通过引用将对象传递给函数一样,也应该从函数返回引用,以避免对象发生不必要的复制。但有时不可能通过引用返回对象,例如编写重载的operator和其他类似运算符时。永远都不要返回指向局部对象的引用或指针,局部对象会在函数退出时被销毁。
自C++11以后,C++语言支持移动语义,允许高效地按值返回对象,而不是使用引用语义。
通过应用捕获异常
应该通过引用捕捉异常,以避免分片和额外的复制。抛出异常的性能开销很大,因此任何提升效率的小事情都是有帮助的。高频函数,最好可以通过返回值等判断错误,避免抛出异常。
使用移动语义
应该为类实现移动构造函数和移动赋值运算符,以允许C++编译器为类对象使用移动语义。
void handleMessage(string & message) // f1
{
cout << “handleMessage with lvalue reference: ” << message << endl;
}
void handleMessage(string && message) // f2
{
cout << “handleMessage with rvalue reference: ” << message << endl;
}
string a = “Hello”;
string b = “World”;
handleMessage(a); // lvalue, f1
handleMessage(a + b); // rvalue, f2
handleMessage(“test”); // rvalue, f2
// 如果注释掉f1的话,handleMessage(a)行将会编译报错,可以使用move增加移动语义。
// handleMessage(move(a));
void helper(string && message)
{
;
}
void handleMessage2(string && message)
{
helper(move(message));
}
有名字的变量是左值,有名字的右值变量也是左值,如handleMessage2函数中的参数message,在handleMessage2函数内使用message时,它本身就是左值,因此调用helper的时候,需要使用move。
对类增加移动语义,就是需要类实现移动构造函数和移动复制预算符。并且,这两个运算符应该使用noexcept限定符标记。
class TestMove
{
public:
// …
TestMove(TestMove && src) noexcept // move constructor
{
moveFrom(src);
}
TestMove & operator = (TestMove && rhs) noexcept
{
if(this == &rhs)
return *this;
cleanup();
moveFrom(rhs);
return *this;
}
// …
private:
void moveFrom(TestMove && src) noexcept
{
nData = src.nData;
pMessage = src.pMessage;
src.nData = 0;
src.pMessage = nullptr;
}
void cleanup() noexcept
{
delete[] pMessage;
pMessage = nullptr;
nData = 0;
}
int nData;
char * pMessage;
}
可通过使用move和swap方法,来替代moveFrom辅助函数。如果上面的TestMove类,增加了其他类型(如string等)的属性,上述的moveFrom需要被修改,这很容易被遗漏,造成bug;因此可以去掉moveFrom函数,另外将释放内存的操作,放到析构函数中实现,那么可以修改上面的类的移动语义。
class TestMove
{
public:
~TestMove()
{
if(nullptr != pMessage)
delete[] pMessage;
pMessage = nullptr;
}
TestMove(TestMove && src) noexcept // move constructor
{
swap(*this, src);
}
TestMove& operator= (TestMove&& rhs) noexcept
{
TestMove temp(move(rhs));
swap(*this, temp); // 原this的内存,由temp的析构函数负责释放
return *this;
}
}
避免创建临时对象
有些情况下,编译器会创建临时的无名对象。例如,为一个类编写全局operator之后,可对这个 类的对象和其他类型的对象进行加法运算,只要其他类型的对象可转换为这个类的对象即可。如, SpreadsheetCell类的部分定义如下:
class Spreadsheetcell
{
public:
// Other constructors omitted for brevity Spreadsheetcell(double initialvalue);
// Remainder omitted for brevity
};
Spreadsheetcell operator+ (const SpreadsheetCell& Ihs, const SpreadsheetCell& rhs);
这个接收double值的构造函数允许编写下面这样的代码:
Spreadsheetcell myCell(4), aThirdCell;
aThirdCell = myCell + 5.6;
aThirdCell = myCell + 4;
第二行通过参数5.6创建了一个临时Spreadsheetcell对象,然后将myCell和临时对象作为参数调用 operator+把结果保存在aThirdCell中。第三行做了同样的事情,只不过4必须强制转换为double类型,才能 调用SpreadsheetCell的double版构造函数。
这个例子中的重点是:编译器生成了代码,为两个加操作创建了一个额外的无名Spreadsheetcell对象。该对象必 须调用其构造函数和析构函数进行构造和销毁。如果还感到怀疑,可在构造函数和析构函数中插入cout语句, 观察输出。
一般情况下,每当代码需要在较大表达式中将一种类型的变量转换为另一种类型时,编译器都会构造临时 对象。此规则主要适用于函数调用。例如,假设函数的原型如下:
void doSomething(const Spreadsheetcell& s);
可这样调用:
doSomething(5.56);
编译器会使用double版构造函数从5.56构造一个临时的SpreadsheetCell对象,然后把这个对象传入 doSomething()。注意,如果把const从s参数移除,那么再也不能通过常量调用doSomething,而是必须传入 变量。
一般来说,应该避免迫使编译器构造临时对象的情况。尽管有时这是不可避免的,但是至少应该意识到这 项“特性”的存在,这样才不会为实际性能和分析结果而感到惊讶。
编译器还会使用移动语义使临时对象的效率更高。这是要在类中添加移动语义的另一个原因。
预分配内存
比如标准c++容器,增加元素时,容器会自动扩展。如果向这样的容器,插入大量的数据元素,这个扩展行为,就不如预先把容器容量,事先预分配后足够的内存。
使用内联
内联(inline)方法或函数的代码可以直接插到被调用的地方,从而避免函数调用的开销。 一方面,应将所有符合这种优化条件的函数和方法标记为inline(但不要过度使用该功能)。另一方面,编译器会在优化过程中内联一些适当的函数和方法,即使这些函数没有用inline关键字标记, 甚至即使这些函数在源文件(而非头文件)中实现也是如此。可以将高频使用的短小函数,设计为内联函数或方法。
尽可能多的使用缓存
缓存(cache)是指将数据项保存下来供以后使用,从而避免再次获取或重新计算它们。下面是使用缓存的常见场景
•磁盘访问:在程序中应避免多次打开和读取同一个文件。如果内存可用,并且需要频繁访问这个文件, 那么应将文件内容保存在内存中。
•网络通信:如果需要经由网络通信,那么程序会受网络负载的影响而行为不定。将网络访问当成文件 访问处理,尽可能多地缓存静态信息。
•数学计算:如果需要在多个地方使用非常复杂的计算结果,那么执行这种计算一次并共享结果。但是, 如果计算不是非常复杂,那么计算可能比从缓存中提取更快。如果需要确定这种情形,可使用分析器。
•对象分配:如果程序需要大量创建和使用短期对象,可以考虑使用本章后面讨论的对象池。
•线程创建:这个任务也很慢。可将线程“缓存”在线程池中,类似于在对象池中缓存对象。
缓存失效
缓存的数据往往是底层信息的副本。在缓存的生命周期中,原始数据可能发生变化。“缓存失效”机制是指:当底层数据发生变化时,必须 停止使用缓存的信息,或重新填写缓存。
对象池
存在不同类型的对象池。一种对象池是一次分配一大块内存,此时,对象池就地创建多个较小对象。可将 这些对象分发给客户,在客户完成时重用它们,这样就不必另外调用内存管理器为各个对象分配内存或解除内 存分配。可参考小型对象分配器的实现。
另一类对象池。如果程序需要大量同类型的短期对象,这些对象的构造函数开销很大(例如构造函 数要创建很大的、预先指定大小的矢量来存储数据),分析器确认这些对象的内存分配和释放是性能瓶颈,就可 为这些对象创建对象池或缓存。每当代码中需要一个对象时,可从对象池中请求一个。当用完对象时,将这个 对象返回对象池中。对象池只创建一次对象,因此对象的构造函数只调用一次,而不是每次需要使用时都调用。
性能分析工具
需要剖析程序,判断哪些部分的代码需要优化。有很多可用的剖析工具,可在程序运行时进行分析, 并生成性能数据。大部分剖析工具都提供函数级别的分析功能,可分析程序中每个函数的运行时间(或占总执行 时间的百分比)。在程序上运行剖析工具后,通常可立即判断出程序中的哪些部分需要优化。优化前后的剖析也 有助于证明优化是否有效。
Microsoft Visual C++2017,就有了一个强大的内建剖析器。如果未使 用Visual C++, Microsoft提供了 Community版本,可供学生、开源开发人员和个人开发人员免费使用,以创建 免费和付费的应用程序。对于人数不超5人的小公司,它也是免费的。另一个很好的剖析工具是来自IBM的 Rational PurifyPluSo还有一些免费的较小剖析工具:Very Sleepy和Luke Stackwalker是Windows上流行的剖析 器,Valgrind和gprof是UNIX/Linux系统上著名的剖析器,此外还有许多其他选择。
gprof的使用有三个步骤:
(1) 用一个特殊标志编译程序,允许下丄次运行程序时记录原始的执行信息。使用GCC作为编译器时,这 个标志是・pg,例如:
gcc -lstdc++ -std=c++17 -pg -o test test.cpp DBTest.cpp
(2) 接下来运行程序。这次运行应该在工作目录下生成gmon.out文件。运行程序时要有耐心,因为第一个 版本的程序非常慢。
(3) 最后一步是运行gprof命令来分析gmon.out剖析信息,并生成一份(大致)可读的报告。gprof输出至标 准输出,因此需要将输出重定向到一个文件:
gprof namedb gmon.out > gprof_analysis.out
.out文件内容如下
|
index |
% time |
self |
children |
called |
name |
|
|
[1] |
100.0 |
0.00 |
0.21 |
main [1] |
||
|
0.02 |
0.18 |
1/1 |
NameDB:: |
NameDB [2] |
||
|
0.00 |
0.01 |
1/1 |
NameDB:: |
~NameDB [13] |
||
|
0.00 |
0.00 |
3/3 |
NameDB:: |
getNameRank [28] |
||
|
[2] |
95.2 |
0.02 |
0.18 |
1 |
NameDB:: |
NameDB [2] |
|
0.02 |
0.16 |
500500/500500 |
NameDB:: |
:nameExistsAndlncrement |
||
|
[3] |
0.00 |
0.00 |
1000/1000 |
NameDB:: |
:addNewName [24] |
|
|
0.00 |
0.00 |
1/1 |
map: : map |
> [87] |
以下列表解释了上述各列。
• index:通过这个索引可在调用图中检索这一条目。
• %time:这个函数及其后代执行时间占程序总执行时间的百分比。
• self:函数本身执行的秒数。
• children:这个函数后代执行的秒数。
• call:这个函数调用的频率。
• name:函数的名称。如果函数名后跟一个放在方括号中的数字,那么这个数字表示调用图中的另一个
索引。
熟练掌握测试技术
测试分为白盒测试和黑盒测试两种。白盒测试中,测试者了解程序的内部原理;黑盒测试中,在测试程序 功能时,不需要了解任何实现细节。在专业级项目中,这两类测试都十分重要。黑盒测试是最基本的方法,它 通常建立用户行为的模型。例如,黑客测试可分析诸如按钮的界面组件。如果测试者单击按钮,却未看到任何 变化,则程序中明显存在bug。
黑盒测试不能包罗一切。现代程序都很庞大,我们无法完全做到:模拟单击所有的按钮,提供每类输入, 执行命令的所有组合。白盒测试是必需的,如果知道测试代码是在对象或子系统级别编写的,则更能方便地确 保测试涵盖代码中的所有路径。这有助于确保测试范围。与黑客测试相比,白盒测试更容易编写和自动完成。 白盒测试技巧,是程序员在开发期间使用的技术。
单元测试
单元测试可从多个方面为你提供保护:
(1) 证实功能确实能够工作。只有通过一些代码来真正使用类,才能大体知道类的行为。
(2) 如果最新引入的更改造成破坏,单元测试可首先发岀警告。这种用法称为“回归测试”,将在本章后面 进行介绍。
(3) 在开发过程中使用时,将迫使开发人员从头修复问题。如果单元测试失败时无法签入,将不得不立即 解决问题。
(4) 单元测试允许在其他代码就绪前尝试自己的代码。首次开始编程时,可以编写整个程序并首次运行该 程序。采用这种方法时,专业程序规模过大,因此需要能独立地测试组件。
(5) 最后,单元测试提供了一个使用案例,这也是比较重要的。作为附带作用,单元测试为其他编程人员 提供极佳的参考代码。如果一位同事需要使用你的数学库来了解如何执行矩阵乘法,你可以指点他完成适当的 测试。
编写单元测试时,需要考虑如下问题:
(1) 编写的这段代码有什么作用?
(2) 通常釆用什么方式调用每个方法?
(3) 调用者可能破坏方法的哪些前置条件?
(4) 可能以哪些方式误用每个方法?
(5) 预计将哪类数据作为输入?
(6) 预计不使用哪类数据作为输入?
(7) 什么是边缘情形或例外情形?
再考虑上面的问题后,可以将测试用例分类如下:
•基本测试
•错误测试
•本地化测试
•错误输入测试
•复杂的测试
测试框架
Visual C++内置了一个测试框架。使用单元测试框架的好处在于允许开发人员专注于编写测试,不需要耗 费精力去设置测试、构建测试逻辑以及收集结果。Google Test 和 Boost Test Library是可用于 C++的框架。它们都包括对测试开 发人员有用的很多实用工具,也包括用于控制结果的自动输出的选项。
集成测试
集成测试的范围是组件结合区域。单元测试通常在单个类的级别上进行,而集成测试通常涉及两个类或更 多类。集成测试擅长测试两个组件(往往由两个不同的编程人员所写)之间的交互。事实上,在编写集成测试期 间,经常能发现设计中的重要不兼容之处。比如,数据存取测试,可以发现一些数据类型或编码问题。
系统测试
系统测试在高于集成测试的级别操作。系统测试通盘分析程序。系统测试中会有虚拟用户,用来模拟使用 程序的人。当然,必须为虚拟用户提供执行操作的脚本。其他系统测试依赖于脚本或一组固定的输入,也依赖 于预期的输出。与单元测试和集成测试类似,系统测试执行具体的测试,并预期具体的结果。经常使用系统测试来确保不 同功能可结合在一起工作。
从理论上讲,完全经过系统测试的程序包含每项功能的每个测试。这种方法很快就会变得笨重不堪,但仍 需要努力测试多项功能的组合。例如,图形程序的系统测试导入图像,旋转图像,应用模糊滤镜,转换为黑白 图像,然后保存图像。系统测试会将保存的图像与包含预期结果的文件进行比较。
令人遗憾的是,关于系统测试的具体规则很少,因为系统测试高度依赖于实际应用程序。如果应用程序处 理文件时不存在用户交互,那么系统测试的编写与单元测试和集成测试十分类似。对于图形程序而言,虚拟用 户方式是最合适的。对于服务器应用程序而言,可能需要构建存根客户端来模拟网络流量。重点在于,实际测试的是程序的实际使用情况,而非程序某部分的实际使用情况。
回归测试
回归测试更多是测试概念而非具体测试类型。具体想法是:一旦一个功能可以工作,开发人员就倾向于将它放在一边,并假设它将继续工作。遗憾的是,新功能和其他代码更改通常会悄无声息地破坏以前可以正常工 作的功能。
回归测试常用于功能的完好性检查,这些功能在一定程度上是完整的、可工作的。如果一项更改破坏了功能,编写得当的回归测试会阻止其通过。可借助几款商业软件包和非商业软件包为各类应用程序较方便地编写测试脚本。
熟练掌握调试技术
崩溃转储
确保程序创建崩溃转储,也称为内存转储、核心转储等。崩溃转储是一个转储文件,会在应用程序崩溃时 创建。它包含以下信息:在崩溃时哪个线程正在运行、所有线程的调用堆栈等。创建这种转储的方式与平台相 关,所以应查阅平台的文档,或使用第三方库。Breakpad就是这样一个开源 跨平台库,可用来写入和处理崩溃转储。
还要确保建立符号服务器和源代码服务器。符号服务器用于存储软件发布二进制版本的调试符号,这些符 号在以后用于解释来自客户的崩溃转储。调试崩溃转储 时,源代码服务器用于下载正确的源代码,以修订创建崩溃转储的软件。
分析崩溃转储的具体过程取决于平台和编译器,所以应查阅相关的文档。 就个人经验而论,崩溃转储的价值常比一千份bug报告更高。
CDB与GDB都可以分析dump文件。
调试不可重现bug
修复不可重现的bug比修复可重现的bug困难得多。通常,能了解到的信息很少,必须进行大量猜测。不过,也有一些有帮助的策略:
(1)尝试将不可重现的bug转换为可重现的bug。通过充分的猜测,通常可确定bug的大致位置。花一些时间尝试重现bug。一旦有了可重现的bug,就可以使用前面描述的技术找到bug的根源。
(2) 分析错误日志。如果程序根据前面的描述带有生成错误日志的功能,那么这一点很容易实现。应该筛 查这些信息,因为bug出现之前记录的任何错误都有可能会对bug本身有贡献。如果幸运(或者程序写得好), 程序会记录手头要处理的bug的准确原因。
(3) 获取和分析跟踪。如果程序带有跟踪输出,那么这一点很容易实现。在发生bug时,可能获得一份跟踪的副本。通过这些跟踪,应该能找到代码中bug的正确位置。
(4)如果有的话,检查崩溃/内存文件。有些平台会在应用程序异常终止时生成内存转储文件。在UNIX和 Linux,这些内存转储文件称为核心文件(core dump)每个平台都提供了分析这些内存转储文件的工具。例如, 这些工具可用来生成应用程序的堆栈跟踪信息,或查看应用程序崩溃之前内存中的内容。
(5) 检查代码。遗憾的是,这往往是检查不可重现bug的根源的唯一策略。令人惊讶的是,这种策略往往奏效。检查代码时,甚至是检查自己编写的代码时,如果站在刚才发生的bug的视角,通常可以找到之前忽视 的错误。不建议花很长时间盯着代码,而手工跟踪代码执行路径往往可以直接找到问题所在。记录稳定版本日志,非常重要,因为可以缩小问题发生的大致版本范围。
(6) 使用内存观察工具。这类工具往往会警告一些未必导致程序行为异常的内存错误,但这些问题可能是 手头bug的根源。
(7) 提交或更新bug报告。即使不能马上,发现bug的根源,如果再次遇到问题,bug报告也会是描述前面做出的尝试的有用记录。
(8) 如果无法找到引起bug的根本原因,务必添加额外的日志记录或跟踪。这样,bug下次出现时,将有更大的机会找到原因。
一旦找到不可重现bug的根源,就应该创建可重现的测试用例,并将其转移至“可重现bug”类别。重要 的是在实际修复bug之前重现这个bug。否则,怎么才能测试bug是否修复?调试不可重现bug的一个常见错误是在代码中修复错误的问题。不能重现bug,也不知道是否真正修复了这个bug,因此几个月后当这个bug 再次出现时,没有什么可惊讶的。
修复历史bug,往往需要花费大量的精力,需要坚韧的毅力,而且有必要提升协作等级,发挥团队的力量。往往可以通过review怀疑的代码,一点点的找出可疑或非法用例,来慢慢剥离问题,抽丝剥茧,问题分解,都是常用的方法。还有些分布式系统的疑难bug与时序有关,这时候需要详细分析相关的顺序图(没有的话,画出来),找出可能的时序问题。有些bug可能与同步异步混用有关,归根结底也是时序混乱造成的。举个例子,当两个进程A和B,他们两个公用一块共享内存C。A传递一个信号给B,接收C中的某段数据的更新,B收到数据后memcpy C缓存中的一大段数据到本地,用于更新本地缓存或落地到数据库中。然后,B立即发信号给A,表示自己拿到了数据缓存C的更新。A再收到确认信号后,马上开始重用C中的这块共享内存,并修改了这块内存的数据。于是,当生产环境下,运行时,就可能发生,B存储到数据库中的数据,有一部分数据是损坏的,或不是想要刷新到数据库中的数据。这是实际案例,也是经历了大概3年的时间,在我经手后,解决的。并不是我有多厉害,只是我花了时间,去画时序图,去研究,去分解问题,逐渐剥离了干扰项,发现了问题的根源。
常见的内存分配错误
为调试内存问题,应该熟悉可能发生的内存错误类型。下面介绍内存错误的分类。每种内存错误都包含一 个演示错误的简短代码示例,并列出可能观察到的症状。注意,症状并不等同于bug本身:症状是由bug引起 的可观察到的行为。
内存错误表
|
错误类型 |
|
内存泄漏 |
|
使用不匹配的分配和释放操作 |
|
多次释放内存 |
|
释放未分配的内存 |
|
释放堆栈内存 |
|
访问无效内存 |
|
访问已释放的内存 |
|
访问不同分配中的内存 |
|
读取未初始化的内存 |
|
缓冲区溢出 |
调试多线程
C++包含一个线程库,里面提供了多线程和线程间同步的机制。这个线程库在第23章讨论过。多线程的 C++程序很常见,因此考虑多线程程序调试时的特殊情况非常重要。多线程程序的bug往往因为操作系统调度中时序的不同而引起,很难重现。因此,调试多线程程序需要釆用一套特殊技术。
(1)使用调试器:调试器很容易诊断某些多线程问题,例如死锁。出现死锁时,调试过程会进入调试器, 检查不同的线程。在调试器中,可以看到哪些线程被阻塞,它们在哪行代码被阻塞。将这些信息与跟踪日志相 比较,可以看出程序是如何进入死锁情形的,这足以解决死锁。
(2) 使用基于日志的调试:调试多线程程序时,基于日志的调试有时在调试某些问题时比使用调试器更有效。在程序的临界区之前和之后,以及获得锁之前和释放锁之后添加日志语句。基于日志的调试对观察竞争条 件极为有效,但添加日志语句会轻微改变运行时时序,这可能会隐藏bug。
(3) 插入强制休眠和上下文切换:如果一致地重现问题有困难,或者对问题发生的根源有感觉,但是想要 验证根源,那么可以让线程睡眠特定的时间,强制执行特定的线程调度行为。〈thread〉头文件在std::this_thread 名称空间中定义了可实现休眠的sleep_until()和sleep_for()函数。将睡眠时间分别指定为std::time_point或 std::duration,两者都是第20章讨论的chrono库的一部分。在释放锁之前休眠几秒,或者在对某个条件变量发 岀信号前休眠几秒,或在访问共享数据之前休眠几秒,可能表现出争用条件(如果不休眠,则可能无法检测到)。 如果通过这种调试技术找到了问题的根源,那么必须修复这个问题,这样在移除了这些强制休眠和上下文切换 之后,代码就能正常工作。这种把这些强制休眠和上下文切换留在程序中,进而“解决问题”的方法是错误的。
(4) 核查代码:核查线程同步代码有助于解决争用条件。不可能反复尝试己发生的情形,直到看出该情形 是如何发生的。在代码注释中记下这些“证据”是无害的。另外,请同事与自己一起调试,他可能会看到你忽略的东西。
版权声明:本文图片和内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送联系客服 举报,一经查实,本站将立刻删除,请注明出处:https://www.4kpp.com/32931.html